Object: Name and Value
Humoon
2022-05-02
library(lobstr)Name and Value of Objects
Name
指针
对象的变量名是一个常量指针,指向一个对象所在的地址。
x <- 1:3
y <- x # x, y 为指向同一个向量的指针
z <- 1:3
obj_addr(x) # 对象的唯一标识符,并非内存中真正的地址#> [1] "0x1daa7956720"obj_addr(y)#> [1] "0x1daa7956720"obj_addr(z) # 可见,z 指向的是另一个对象#> [1] "0x1daa79fb1d0"# 几种访问函数的方式,第二个指向的不是同一个潜在函数对象
# 可能是因为某个包的 mean() 覆盖了 base::mean()
mean %>% obj_addr()#> [1] "0x1daa79f6c38"base::mean %>% obj_addr()#> [1] "0x1da9cf7eff0"get("mean") %>% obj_addr()#> [1] "0x1daa79f6c38"evalq(mean) %>% obj_addr()#> [1] "0x1daa79f6c38"match.fun("mean") %>% obj_addr()#> [1] "0x1da9cf7eff0"不规则变量名
R 中变量的命名规则:名称只能包含 a~z,
A~Z,
下划线_和句点.,不能有空格,也不能以下划线_开头,而且不能是
R 中的 reserved word
违反命名规则的变量名,要用反引号括起来,才能被识别
c %>% class() # c是一个内置函数,所以一般变量不能以'c'命名#> [1] "function"c#> function (...) .Primitive("c")`x+1` <- function(n) n + 1
`x+1`#> function(n) n + 1`x+1`(3)#> [1] 4修改时复制(Copy on Modify)
R 中的对象一般不允许被修改(就像 JS
中的const常量),这对数据安全有好处。
一旦涉及数据修改,R 常常会 copy 一份数据的副本,然后在副本上修改数据——这是 R 速度慢的一个重要原因。
特别是 for 循环,每次迭代都会对数据产生一次或多次拷贝。purrr 包的高阶函数比较快就是因为避免了这一点。
数字向量
有多个指针指向同一个对象,且通过其中一个指针修改该对象时,会生成该对象的一个副本(一个新对象)。修改作用在这个副本上,然后使被修改的指针指向这个副本。
x <- c(1, 2, 3) cat(tracemem(x), "\n") # tracemen()跟踪指针指向的对象,每当这个对象被复制,会打印一条说明#> <000001DAAE36C0B8>y <- x y[3] <- 4L # x, y 均指向对象,通过 y 修改对象时,发生 copy#> tracemem[0x000001daae36c0b8 -> 0x000001daae3843f8]: eval eval eval_with_user_handlers withVisible withCallingHandlers handle timing_fn evaluate_call <Anonymous> evaluate in_dir in_input_dir eng_r block_exec call_block process_group.block process_group withCallingHandlers process_file <Anonymous> <Anonymous> do.call eval eval eval eval eval.parent localobj_addr(x)#> [1] "0x1daae36c0b8"obj_addr(y)#> [1] "0x1daae3843f8"y[3] <- 5L # 不会 copy,因为只有唯一指针 y 指向对象 obj_addr(y)#> [1] "0x1daae3843f8"untracemem(y) # 关闭跟踪对象作为参数传递给函数,并在函数内部修改对象时,也会创建对象的副本。函数外部的变量名仍指向未被修改的原对象
v1 <- c(1, 2, 3) cat(tracemem(v1), "\n")#> <000001DAAE624AE8>modify1 <- function(x) { x[1] <- 0 x } modify1(v1) %>% obj_addr()#> tracemem[0x000001daae624ae8 -> 0x000001daae640e48]: modify1 obj_addr_ obj_addr %>% eval eval eval_with_user_handlers withVisible withCallingHandlers handle timing_fn evaluate_call <Anonymous> evaluate in_dir in_input_dir eng_r block_exec call_block process_group.block process_group withCallingHandlers process_file <Anonymous> <Anonymous> do.call eval eval eval eval eval.parent local#> [1] "0x1daae640e48"v1 # 外部的 v1 未被修改#> [1] 1 2 3tracemem(v1)#> [1] "<000001DAAE624AE8>"
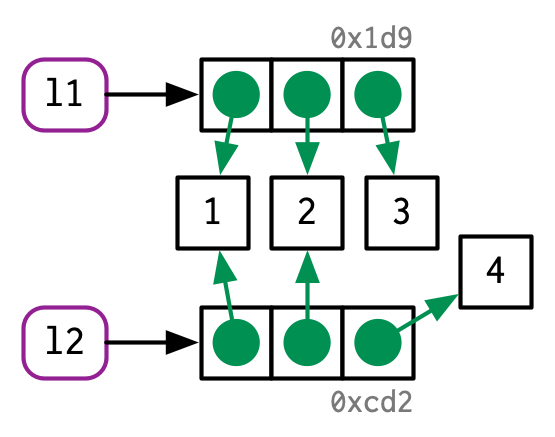
列表
为了节省空间,列表储存的不是对象,而是指针。修改列表时,只有变化的元素会复制。
l1 <- list(1, 2, 3)
l2 <- l1
l2[[3]] <- 4 # 拷贝机制启动,但拷贝的是指针,而不是 value,这是浅拷贝
lobstr::ref(l1, l2)#> █ [1:0x1daa6c99b68] <list>
#> ├─[2:0x1daa56f8ce0] <dbl>
#> ├─[3:0x1daa56f8d18] <dbl>
#> └─[4:0x1daa56f8d50] <dbl>
#>
#> █ [5:0x1daa6db2de8] <list>
#> ├─[2:0x1daa56f8ce0]
#> ├─[3:0x1daa56f8d18]
#> └─[6:0x1daa56f8e30] <dbl>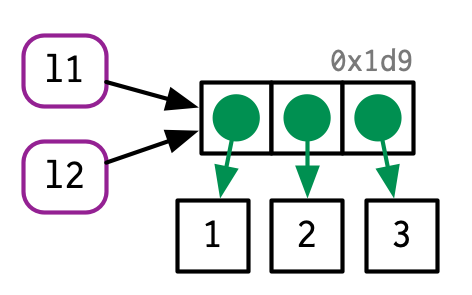
a <- 1:10
b <- list(a, a)
c <- list(b, a, 1:10)
lobstr::ref(a)#> [1:0x1daa2978200] <int># 第一行是指向列表的指针,2、3行是指向列表元素的指针
# b的两个元素,指向同一个向量
lobstr::ref(b) #> █ [1:0x1daab074838] <list>
#> ├─[2:0x1daa2978200] <int>
#> └─[2:0x1daa2978200]lobstr::ref(c) # c的第三个元素不同于a指向的向量#> █ [1:0x1daa9c9cbf8] <list>
#> ├─█ [2:0x1daab074838] <list>
#> │ ├─[3:0x1daa2978200] <int>
#> │ └─[3:0x1daa2978200]
#> ├─[3:0x1daa2978200]
#> └─[4:0x1daa2724f90] <int>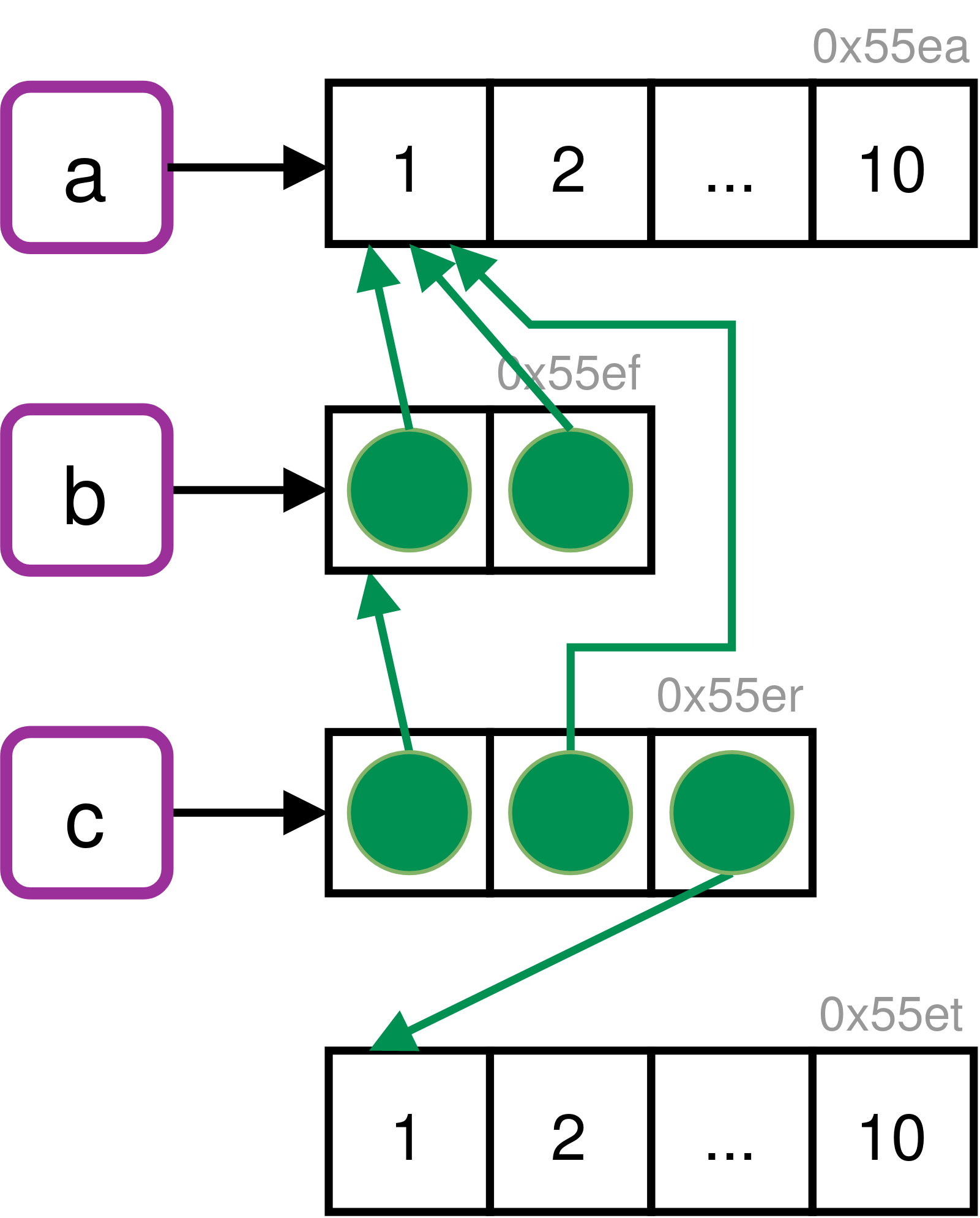
x <- list(1:10)
ref(x)#> █ [1:0x1daa5fa5d68] <list>
#> └─[2:0x1daa57534c8] <int>x[[2]] <- x
ref(x)#> █ [1:0x1daaca3e858] <list>
#> ├─[2:0x1daa57534c8] <int>
#> └─█ [3:0x1daa5fa5d68] <list>
#> └─[2:0x1daa57534c8]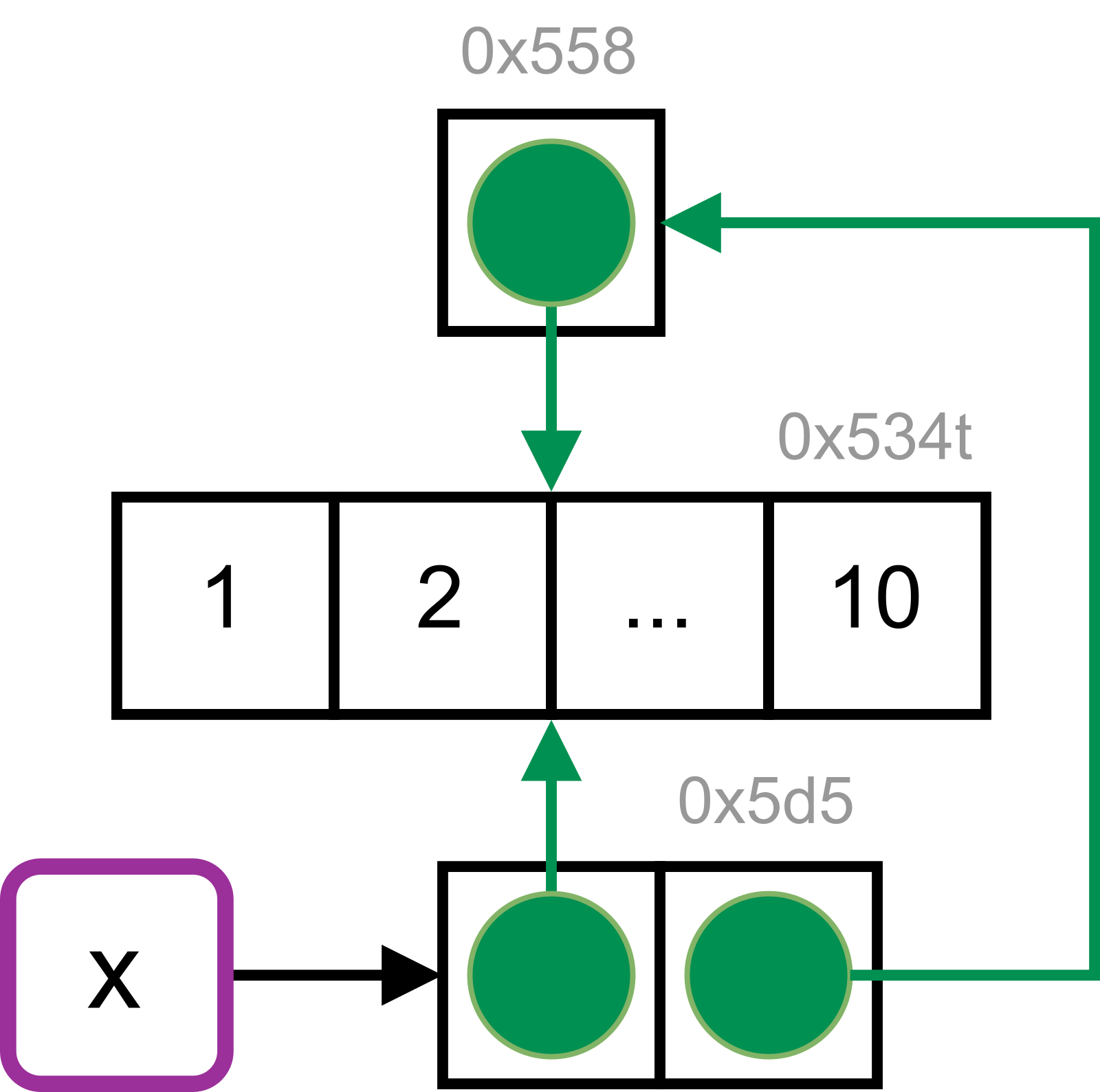
数据框
数据框本质上是一个列表,储存的都是指向列向量的指针。

d1 <- data.frame(x = c(1, 5, 6), y = c(2, 4, 3))
d2 <- d1
d3 <- d1
ref(d1, d2, d3)#> █ [1:0x1daa7c31cd8] <df[,2]>
#> ├─x = [2:0x1daad9f05c8] <dbl>
#> └─y = [3:0x1daad9f0578] <dbl>
#>
#> [1:0x1daa7c31cd8]
#>
#> [1:0x1daa7c31cd8]# 修改列,该列复制;其他列扔指向原对象
d2[, 2] <- d2[, 2] * 2
ref(d1, d2)#> █ [1:0x1daa7c31cd8] <df[,2]>
#> ├─x = [2:0x1daad9f05c8] <dbl>
#> └─y = [3:0x1daad9f0578] <dbl>
#>
#> █ [4:0x1daa7c518d8] <df[,2]>
#> ├─x = [2:0x1daad9f05c8]
#> └─y = [5:0x1daadb21b68] <dbl>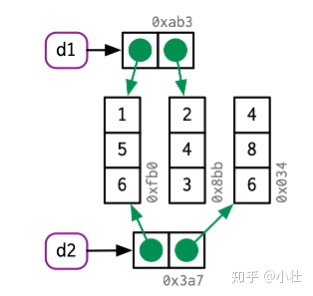
# 修改行,必须复制每一列
d3[1, ] <- d3[1, ] * 3
ref(d1, d3)#> █ [1:0x1daa7c31cd8] <df[,2]>
#> ├─x = [2:0x1daad9f05c8] <dbl>
#> └─y = [3:0x1daad9f0578] <dbl>
#>
#> █ [4:0x1daad6bf358] <df[,2]>
#> ├─x = [5:0x1daadc39218] <dbl>
#> └─y = [6:0x1daadc39178] <dbl>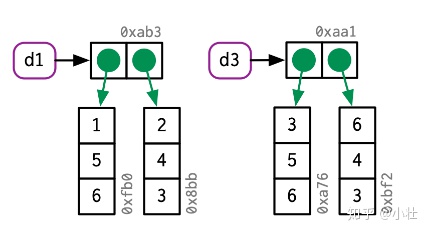
字符串向量
也是指针的向量。每个指针指向一个字符串,这些字符串位于全局字符串池中。
x <- c("a", "a", "abc", "d")
ref(x, character = TRUE)#> █ [1:0x1daadcf9028] <chr>
#> ├─[2:0x1da9a6ebb08] <string: "a">
#> ├─[2:0x1da9a6ebb08]
#> ├─[3:0x1daa8c4ef08] <string: "abc">
#> └─[4:0x1da9a9402e8] <string: "d">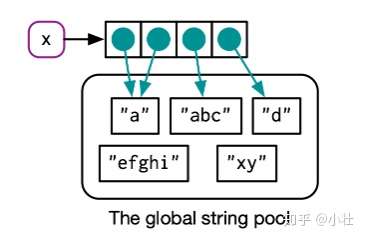
唯一指针
只有一个指针指向对象时,修改对象不会发生复制。
但 Rstudio 中与 Console 中不同,Rstudio 中仍要复制。本文件是在 Rstudio 中生成的,因此下面的代码段仍然含有复制。
v <- c(1,2)
obj_addr(v)#> [1] "0x1daadbd5f08"v[[2]] <- 5
obj_addr(v)#> [1] "0x1daadbf5648"但是,R 对指针数量的判断不够智能。如两个指针指向一个对象,其中一个被删除后,R 却不知道,仍然以为有两个指针。因此会产生很多不必要的对象拷贝。
环境对象
总是被就地修改,不会 copy
此功能非常有用,可以实现闭包、R6类型系统,等等
解构赋值(Unpacking Assignment)
zeallot 包提供的 %<-% 和 %>-%
函数
library(zeallot)
# unpack vector
c(lat, lng) %<-% c(38.061944, -122.643889)
lat#> [1] 38.06194lng#> [1] -122.6439# unpack list
coords_list <- function() {
list(38.061944, -122.643889)
}
c(lat, lng) %<-% coords_list()
lat#> [1] 38.06194lng#> [1] -122.6439# unpack regression result
c(inter, slope) %<-% coef(lm(mpg ~ cyl, data = mtcars))
inter#> [1] 37.88458slope#> [1] -2.87579# unpack data.frame
c(mpg, cyl, disp, hp) %<-% mtcars[, 1:4]
head(mpg)#> [1] 21.0 21.0 22.8 21.4 18.7 18.1# unpack nested values
c(a, c(b, d), e) %<-% list("begin", list("middle1", "middle2"), "end")
a#> [1] "begin"b#> [1] "middle1"d#> [1] "middle2"e#> [1] "end"# unpack character string
c(ch1, ch2, ch3) %<-% "abc"
ch1#> [1] "a"ch2#> [1] "b"ch3#> [1] "c"# unpack Date
c(y, m, d) %<-% Sys.Date()
y#> [1] 2022m#> [1] 5d#> [1] 2# ... rest of
c(begin, ...middle, end) %<-% list(1, 2, 3, 4, 5)
begin#> [1] 1middle#> [[1]]
#> [1] 2
#>
#> [[2]]
#> [1] 3
#>
#> [[3]]
#> [1] 4# place holder
c(min_wt, ., ., mean_wt, ., max_wt) %<-% summary(mtcars$wt)
min_wt#> [1] 1.513mean_wt#> [1] 3.21725max_wt#> [1] 5.424# 向右的解构赋值符号 %->%
mtcars %>%
subset(hp > 100) %>%
aggregate(. ~ cyl, data = ., FUN = . %>% mean() %>% round(2)) %>%
transform(kpl = mpg %>% multiply_by(0.4251)) %->%
c(cyl, mpg, ...rest)
cyl#> [1] 4 6 8LS0tDQp0aXRsZTogIk9iamVjdDogTmFtZSBhbmQgVmFsdWUiDQpzdWJ0aXRsZTogIiINCmF1dGhvcjogIkh1bW9vbiINCmRhdGU6ICJgciBTeXMuRGF0ZSgpYCINCm91dHB1dDogaHRtbF9kb2N1bWVudA0KZG9jdW1lbnRjbGFzczogY3RleGFydA0KY2xhc3NvcHRpb246IGh5cGVycmVmLA0KLS0tDQoNCmBgYHtyIHNldHVwLCBpbmNsdWRlID0gRkFMU0V9DQpzb3VyY2UoIi4uL1JtYXJrZG93bi10ZW1wbGF0ZS9SbWFya2Rvd25fY29uZmlnLlIiKQ0KDQojIyBnbG9iYWwgb3B0aW9ucyA9PT09PT09PT09PT09PT09PT09PT09PT09PT09PT09PT09PQ0Ka25pdHI6Om9wdHNfY2h1bmskc2V0KA0KICB3aWR0aCA9IGNvbmZpZyR3aWR0aCwNCiAgZmlnLndpZHRoID0gY29uZmlnJGZpZy53aWR0aCwNCiAgZmlnLmFzcCA9IGNvbmZpZyRmaWcuYXNwLA0KICBvdXQud2lkdGggPSBjb25maWckb3V0LndpZHRoLA0KICBmaWcuYWxpZ24gPSBjb25maWckZmlnLmFsaWduLA0KICBmaWcucGF0aCA9IGNvbmZpZyRmaWcucGF0aCwNCiAgZmlnLnNob3cgPSBjb25maWckZmlnLnNob3csDQogIHdhcm4gPSBjb25maWckd2FybiwNCiAgd2FybmluZyA9IGNvbmZpZyR3YXJuaW5nLA0KICBtZXNzYWdlID0gY29uZmlnJG1lc3NhZ2UsDQogIGVjaG8gPSBjb25maWckZWNobywNCiAgZXZhbCA9IGNvbmZpZyRldmFsLA0KICB0aWR5ID0gY29uZmlnJHRpZHksDQogIGNvbW1lbnQgPSBjb25maWckY29tbWVudCwNCiAgY29sbGFwc2UgPSBjb25maWckY29sbGFwc2UsDQogIGNhY2hlID0gY29uZmlnJGNhY2hlLA0KICBjYWNoZS5jb21tZW50cyA9IGNvbmZpZyRjYWNoZS5jb21tZW50cywNCiAgYXV0b2RlcCA9IGNvbmZpZyRhdXRvZGVwDQopDQpgYGANCg0KYGBge3J9DQpsaWJyYXJ5KGxvYnN0cikNCmBgYA0KDQojIyBOYW1lIGFuZCBWYWx1ZSBvZiBPYmplY3RzDQoNCiMjIyBOYW1lDQoNCiMjIyMg5oyH6ZKIDQoNCuWvueixoeeahOWPmOmHj+WQjeaYr+S4gOS4quW4uOmHj+aMh+mSiO+8jOaMh+WQkeS4gOS4quWvueixoeaJgOWcqOeahOWcsOWdgOOAgg0KDQpgYGB7cn0NCnggPC0gMTozDQp5IDwtIHggIyB4LCB5IOS4uuaMh+WQkeWQjOS4gOS4quWQkemHj+eahOaMh+mSiA0KeiA8LSAxOjMNCg0Kb2JqX2FkZHIoeCkgIyDlr7nosaHnmoTllK/kuIDmoIfor4bnrKbvvIzlubbpnZ7lhoXlrZjkuK3nnJ/mraPnmoTlnLDlnYANCm9ial9hZGRyKHkpDQpvYmpfYWRkcih6KSAjIOWPr+inge+8jHog5oyH5ZCR55qE5piv5Y+m5LiA5Liq5a+56LGhDQoNCiMg5Yeg56eN6K6/6Zeu5Ye95pWw55qE5pa55byP77yM56ys5LqM5Liq5oyH5ZCR55qE5LiN5piv5ZCM5LiA5Liq5r2c5Zyo5Ye95pWw5a+56LGhDQojIOWPr+iDveaYr+WboOS4uuafkOS4quWMheeahCBtZWFuKCkg6KaG55uW5LqGIGJhc2U6Om1lYW4oKQ0KbWVhbiAlPiUgb2JqX2FkZHIoKQ0KYmFzZTo6bWVhbiAlPiUgb2JqX2FkZHIoKQ0KZ2V0KCJtZWFuIikgJT4lIG9ial9hZGRyKCkNCmV2YWxxKG1lYW4pICU+JSBvYmpfYWRkcigpDQptYXRjaC5mdW4oIm1lYW4iKSAlPiUgb2JqX2FkZHIoKQ0KYGBgDQoNCiMjIyMg5LiN6KeE5YiZ5Y+Y6YeP5ZCNDQoNClIg5Lit5Y+Y6YeP55qE5ZG95ZCN6KeE5YiZ77ya5ZCN56ew5Y+q6IO95YyF5ZCrIGBh772eemAsIGBB772eWmAsIOS4i+WIkue6v2BfYOWSjOWPpeeCuWAuYO+8jOS4jeiDveacieepuuagvO+8jOS5n+S4jeiDveS7peS4i+WIkue6v2BfYOW8gOWktO+8jOiAjOS4lOS4jeiDveaYryBSIOS4reeahCByZXNlcnZlZCB3b3JkDQoNCui/neWPjeWRveWQjeinhOWImeeahOWPmOmHj+WQje+8jOimgeeUqOWPjeW8leWPt+aLrOi1t+adpe+8jOaJjeiDveiiq+ivhuWIqw0KDQpgYGB7cn0NCmMgJT4lIGNsYXNzKCkgIyBj5piv5LiA5Liq5YaF572u5Ye95pWw77yM5omA5Lul5LiA6Iis5Y+Y6YeP5LiN6IO95LulJ2Mn5ZG95ZCNDQpjDQoNCmB4KzFgIDwtIGZ1bmN0aW9uKG4pIG4gKyAxDQpgeCsxYA0KYHgrMWAoMykNCmBgYA0KDQojIyMg5L+u5pS55pe25aSN5Yi277yIQ29weSBvbiBNb2RpZnnvvIkNCg0KUiDkuK3nmoTlr7nosaEqKuS4gOiIrCoq5LiN5YWB6K646KKr5L+u5pS577yI5bCx5YOPIEpTIOS4reeahGBjb25zdGDluLjph4/vvInvvIzov5nlr7nmlbDmja7lronlhajmnInlpb3lpITjgIINCg0K5LiA5pem5raJ5Y+K5pWw5o2u5L+u5pS577yMUiDluLjluLjkvJogY29weSDkuIDku73mlbDmja7nmoTlia/mnKzvvIznhLblkI7lnKjlia/mnKzkuIrkv67mlLnmlbDmja4tLS0tLS3ov5nmmK8gUiDpgJ/luqbmhaLnmoTkuIDkuKrph43opoHljp/lm6DjgIINCg0K54m55Yir5pivIGZvciDlvqrnjq/vvIzmr4/mrKHov63ku6Ppg73kvJrlr7nmlbDmja7kuqfnlJ/kuIDmrKHmiJblpJrmrKHmi7fotJ3jgIJwdXJyciDljIXnmoTpq5jpmLblh73mlbDmr5TovoPlv6vlsLHmmK/lm6DkuLrpgb/lhY3kuobov5nkuIDngrnjgIINCg0KIyMjIyDmlbDlrZflkJHph48NCg0KMS4gIOaciSoq5aSa5Liq5oyH6ZKIKirmjIflkJHlkIzkuIDkuKrlr7nosaHvvIzkuJTpgJrov4flhbbkuK3kuIDkuKrmjIfpkojkv67mlLnor6Xlr7nosaHml7bvvIzkvJrnlJ/miJDor6Xlr7nosaHnmoTkuIDkuKrlia/mnKzvvIjkuIDkuKrmlrDlr7nosaHvvInjgILkv67mlLnkvZznlKjlnKjov5nkuKrlia/mnKzkuIrvvIznhLblkI7kvb/ooqvkv67mlLnnmoTmjIfpkojmjIflkJHov5nkuKrlia/mnKzjgIINCg0KICAgIGBgYHtyfQ0KICAgIHggPC0gYygxLCAyLCAzKQ0KICAgIGNhdCh0cmFjZW1lbSh4KSwgIlxuIikgIyB0cmFjZW1lbigp6Lef6Liq5oyH6ZKI5oyH5ZCR55qE5a+56LGh77yM5q+P5b2T6L+Z5Liq5a+56LGh6KKr5aSN5Yi277yM5Lya5omT5Y2w5LiA5p2h6K+05piODQogICAgeSA8LSB4DQogICAgeVszXSA8LSA0TCAjIHgsIHkg5Z2H5oyH5ZCR5a+56LGh77yM6YCa6L+HIHkg5L+u5pS55a+56LGh5pe277yM5Y+R55SfIGNvcHkNCiAgICBvYmpfYWRkcih4KQ0KICAgIG9ial9hZGRyKHkpDQogICAgeVszXSA8LSA1TCAjIOS4jeS8miBjb3B577yM5Zug5Li65Y+q5pyJ5ZSv5LiA5oyH6ZKIIHkg5oyH5ZCR5a+56LGhDQogICAgb2JqX2FkZHIoeSkNCiAgICB1bnRyYWNlbWVtKHkpICMg5YWz6Zet6Lef6LiqDQogICAgYGBgDQoNCjIuICDlr7nosaHkvZzkuLrlj4LmlbDkvKDpgJLnu5nlh73mlbDvvIzlubblnKjlh73mlbDlhoXpg6jkv67mlLnlr7nosaHml7bvvIzkuZ/kvJrliJvlu7rlr7nosaHnmoTlia/mnKzjgILlh73mlbDlpJbpg6jnmoTlj5jph4/lkI3ku43mjIflkJHmnKrooqvkv67mlLnnmoTljp/lr7nosaENCg0KICAgIGBgYHtyfQ0KICAgIHYxIDwtIGMoMSwgMiwgMykNCiAgICBjYXQodHJhY2VtZW0odjEpLCAiXG4iKQ0KDQogICAgbW9kaWZ5MSA8LSBmdW5jdGlvbih4KSB7DQogICAgICB4WzFdIDwtIDANCiAgICAgIHgNCiAgICB9DQogICAgbW9kaWZ5MSh2MSkgJT4lIG9ial9hZGRyKCkNCiAgICB2MSAjIOWklumDqOeahCB2MSDmnKrooqvkv67mlLkNCiAgICB0cmFjZW1lbSh2MSkNCiAgICBgYGANCg0KIyMjIyDliJfooagNCg0K5Li65LqG6IqC55yB56m66Ze077yM5YiX6KGo5YKo5a2Y55qE5LiN5piv5a+56LGh77yM6ICM5piv5oyH6ZKI44CC5L+u5pS55YiX6KGo5pe277yM5Y+q5pyJ5Y+Y5YyW55qE5YWD57Sg5Lya5aSN5Yi244CCDQoNCmBgYHtyfQ0KbDEgPC0gbGlzdCgxLCAyLCAzKQ0KbDIgPC0gbDENCmwyW1szXV0gPC0gNCAjIOaLt+i0neacuuWItuWQr+WKqO+8jOS9huaLt+i0neeahOaYr+aMh+mSiO+8jOiAjOS4jeaYryB2YWx1Ze+8jOi/meaYr+a1heaLt+i0nQ0KbG9ic3RyOjpyZWYobDEsIGwyKQ0KYGBgDQoNCjxpbWcgc3JjPSJodHRwOi8vaHVtb29uLWltYWdlLWhvc3Rpbmctc2VydmljZS5vc3MtY24tYmVpamluZy5hbGl5dW5jcy5jb20vaW1nL3R5cG9yYS9KYXZhU2NyaXB0L2wtbW9kaWZ5LTEucG5nIiBhbHQ9ImltZyIgc3R5bGU9Inpvb206NTAlOyIvPg0KDQo8aW1nIHNyYz0iaHR0cDovL2h1bW9vbi1pbWFnZS1ob3N0aW5nLXNlcnZpY2Uub3NzLWNuLWJlaWppbmcuYWxpeXVuY3MuY29tL2ltZy90eXBvcmEvSmF2YVNjcmlwdC9sLW1vZGlmeS0yLnBuZyIgYWx0PSJpbWciIHN0eWxlPSJ6b29tOjUwJTsiLz4NCg0KYGBge3J9DQphIDwtIDE6MTANCmIgPC0gbGlzdChhLCBhKQ0KYyA8LSBsaXN0KGIsIGEsIDE6MTApDQpsb2JzdHI6OnJlZihhKQ0KIyDnrKzkuIDooYzmmK/mjIflkJHliJfooajnmoTmjIfpkojvvIwy44CBM+ihjOaYr+aMh+WQkeWIl+ihqOWFg+e0oOeahOaMh+mSiA0KIyBi55qE5Lik5Liq5YWD57Sg77yM5oyH5ZCR5ZCM5LiA5Liq5ZCR6YePDQpsb2JzdHI6OnJlZihiKSANCmxvYnN0cjo6cmVmKGMpICMgY+eahOesrOS4ieS4quWFg+e0oOS4jeWQjOS6jmHmjIflkJHnmoTlkJHph48NCmBgYA0KDQo8aW1nIHNyYz0iaHR0cHM6Ly9hZHZhbmNlZC1yLXNvbHV0aW9ucy5yYmluZC5pby9pbWFnZXMvbmFtZXNfdmFsdWVzL2NvcHlfb25fbW9kaWZ5X2ZpZzMucG5nIiBhbHQ9ImltZyIgc3R5bGU9Inpvb206MjAlOyIvPg0KDQoNCmBgYHtyfQ0KeCA8LSBsaXN0KDE6MTApDQpyZWYoeCkNCnhbWzJdXSA8LSB4DQpyZWYoeCkNCmBgYA0KDQo8aW1nIHNyYz0iaHR0cHM6Ly9hZHZhbmNlZC1yLXNvbHV0aW9ucy5yYmluZC5pby9pbWFnZXMvbmFtZXNfdmFsdWVzL2NvcHlfb25fbW9kaWZ5X2ZpZzIucG5nIiBhbHQ9ImltZyIgc3R5bGU9Inpvb206MjAlOyIvPg0KDQojIyMjIOaVsOaNruahhg0KDQrmlbDmja7moYbmnKzotKjkuIrmmK/kuIDkuKrliJfooajvvIzlgqjlrZjnmoTpg73mmK/mjIflkJHliJflkJHph4/nmoTmjIfpkojjgIINCg0KIVtdKGh0dHA6Ly9odW1vb24taW1hZ2UtaG9zdGluZy1zZXJ2aWNlLm9zcy1jbi1iZWlqaW5nLmFsaXl1bmNzLmNvbS9pbWcvdHlwb3JhL0phdmFTY3JpcHQvdjItMjAxMWRlNmYxNGFlZWI0NzdjOTE1MTZlZjI4OWIzMmNfNzIwdy5qcGcpDQoNCmBgYHtyfQ0KZDEgPC0gZGF0YS5mcmFtZSh4ID0gYygxLCA1LCA2KSwgeSA9IGMoMiwgNCwgMykpDQpkMiA8LSBkMQ0KZDMgPC0gZDENCnJlZihkMSwgZDIsIGQzKQ0KDQojIOS/ruaUueWIl++8jOivpeWIl+WkjeWItu+8m+WFtuS7luWIl+aJlOaMh+WQkeWOn+WvueixoQ0KZDJbLCAyXSA8LSBkMlssIDJdICogMg0KcmVmKGQxLCBkMikNCmBgYA0KDQohW10oaHR0cDovL2h1bW9vbi1pbWFnZS1ob3N0aW5nLXNlcnZpY2Uub3NzLWNuLWJlaWppbmcuYWxpeXVuY3MuY29tL2ltZy90eXBvcmEvSmF2YVNjcmlwdC92Mi0yMTU5NjQ4NjliM2ExODMxZTg5OGNkZjk3Nzk1Yjk0ZV83MjB3LmpwZykNCg0KYGBge3J9DQojIOS/ruaUueihjO+8jOW/hemhu+WkjeWItuavj+S4gOWIlw0KZDNbMSwgXSA8LSBkM1sxLCBdICogMw0KcmVmKGQxLCBkMykNCmBgYA0KDQohW10oaHR0cDovL2h1bW9vbi1pbWFnZS1ob3N0aW5nLXNlcnZpY2Uub3NzLWNuLWJlaWppbmcuYWxpeXVuY3MuY29tL2ltZy90eXBvcmEvSmF2YVNjcmlwdC92Mi1lZWEwNjU4OWFmMTgyMTdlZWNkYTQwNWY3ZWYwZTc4MV9yLmpwZykNCg0KIyMjIyDlrZfnrKbkuLLlkJHph48NCg0K5Lmf5piv5oyH6ZKI55qE5ZCR6YeP44CC5q+P5Liq5oyH6ZKI5oyH5ZCR5LiA5Liq5a2X56ym5Liy77yM6L+Z5Lqb5a2X56ym5Liy5L2N5LqO5YWo5bGA5a2X56ym5Liy5rGg5Lit44CCDQoNCmBgYHtyfQ0KeCA8LSBjKCJhIiwgImEiLCAiYWJjIiwgImQiKQ0KcmVmKHgsIGNoYXJhY3RlciA9IFRSVUUpDQpgYGANCg0KIVtdKGh0dHA6Ly9odW1vb24taW1hZ2UtaG9zdGluZy1zZXJ2aWNlLm9zcy1jbi1iZWlqaW5nLmFsaXl1bmNzLmNvbS9pbWcvdHlwb3JhL0phdmFTY3JpcHQvdjItYmU1MDRiOGZiOTQ2MGFlY2VhNzJjZDJjYjIxYzgxMWVfNzIwdy5qcGcpDQoNCiMjIyMg5ZSv5LiA5oyH6ZKIDQoNCuWPquacieS4gOS4quaMh+mSiOaMh+WQkeWvueixoeaXtu+8jOS/ruaUueWvueixoeS4jeS8muWPkeeUn+WkjeWItuOAgg0KDQrkvYYgUnN0dWRpbyDkuK3kuI4gQ29uc29sZSDkuK3kuI3lkIzvvIxSc3R1ZGlvIOS4reS7jeimgeWkjeWItuOAguacrOaWh+S7tuaYr+WcqCBSc3R1ZGlvIOS4reeUn+aIkOeahO+8jOWboOatpOS4i+mdoueahOS7o+eggeauteS7jeeEtuWQq+acieWkjeWItuOAgg0KDQpgYGB7cn0NCnYgPC0gYygxLDIpDQpvYmpfYWRkcih2KQ0KdltbMl1dIDwtIDUNCm9ial9hZGRyKHYpDQpgYGANCg0K5L2G5piv77yMUiDlr7nmjIfpkojmlbDph4/nmoTliKTmlq3kuI3lpJ/mmbrog73jgILlpoLkuKTkuKrmjIfpkojmjIflkJHkuIDkuKrlr7nosaHvvIzlhbbkuK3kuIDkuKrooqvliKDpmaTlkI7vvIxSIOWNtOS4jeefpemBk++8jOS7jeeEtuS7peS4uuacieS4pOS4quaMh+mSiOOAguWboOatpOS8muS6p+eUn+W+iOWkmuS4jeW/heimgeeahOWvueixoeaLt+i0neOAgg0KDQojIyMjIOeOr+Wig+WvueixoQ0KDQrmgLvmmK/ooqvlsLHlnLDkv67mlLnvvIzkuI3kvJogY29weQ0KDQrmraTlip/og73pnZ7luLjmnInnlKjvvIzlj6/ku6Xlrp7njrDpl63ljIXjgIFSNuexu+Wei+ezu+e7n++8jOetieetiQ0KDQojIyMg6Kej5p6E6LWL5YC877yIVW5wYWNraW5nIEFzc2lnbm1lbnTvvIkNCg0KKip6ZWFsbG90IOWMheaPkOS+m+eahCBgJTwtJWAg5ZKMIGAlPi0lYCDlh73mlbAqKg0KDQpgYGB7cn0NCmxpYnJhcnkoemVhbGxvdCkNCg0KIyB1bnBhY2sgdmVjdG9yDQpjKGxhdCwgbG5nKSAlPC0lIGMoMzguMDYxOTQ0LCAtMTIyLjY0Mzg4OSkNCmxhdA0KbG5nDQoNCiMgdW5wYWNrIGxpc3QNCmNvb3Jkc19saXN0IDwtIGZ1bmN0aW9uKCkgew0KICBsaXN0KDM4LjA2MTk0NCwgLTEyMi42NDM4ODkpDQp9DQpjKGxhdCwgbG5nKSAlPC0lIGNvb3Jkc19saXN0KCkNCmxhdA0KbG5nDQoNCiMgdW5wYWNrIHJlZ3Jlc3Npb24gcmVzdWx0DQpjKGludGVyLCBzbG9wZSkgJTwtJSBjb2VmKGxtKG1wZyB+IGN5bCwgZGF0YSA9IG10Y2FycykpDQppbnRlcg0Kc2xvcGUNCg0KIyB1bnBhY2sgZGF0YS5mcmFtZQ0KYyhtcGcsIGN5bCwgZGlzcCwgaHApICU8LSUgbXRjYXJzWywgMTo0XQ0KaGVhZChtcGcpDQoNCiMgdW5wYWNrIG5lc3RlZCB2YWx1ZXMNCmMoYSwgYyhiLCBkKSwgZSkgJTwtJSBsaXN0KCJiZWdpbiIsIGxpc3QoIm1pZGRsZTEiLCAibWlkZGxlMiIpLCAiZW5kIikNCmENCmINCmQNCmUNCg0KIyB1bnBhY2sgY2hhcmFjdGVyIHN0cmluZw0KYyhjaDEsIGNoMiwgY2gzKSAlPC0lICJhYmMiDQpjaDENCmNoMg0KY2gzDQoNCiMgdW5wYWNrIERhdGUNCmMoeSwgbSwgZCkgJTwtJSBTeXMuRGF0ZSgpDQp5DQptDQpkDQoNCiMgLi4uIHJlc3Qgb2YNCmMoYmVnaW4sIC4uLm1pZGRsZSwgZW5kKSAlPC0lIGxpc3QoMSwgMiwgMywgNCwgNSkNCmJlZ2luDQptaWRkbGUNCg0KIyBwbGFjZSBob2xkZXINCmMobWluX3d0LCAuLCAuLCBtZWFuX3d0LCAuLCBtYXhfd3QpICU8LSUgc3VtbWFyeShtdGNhcnMkd3QpDQptaW5fd3QNCm1lYW5fd3QNCm1heF93dA0KDQojIOWQkeWPs+eahOino+aehOi1i+WAvOespuWPtyAlLT4lDQptdGNhcnMgJT4lDQogIHN1YnNldChocCA+IDEwMCkgJT4lDQogIGFnZ3JlZ2F0ZSguIH4gY3lsLCBkYXRhID0gLiwgRlVOID0gLiAlPiUgbWVhbigpICU+JSByb3VuZCgyKSkgJT4lDQogIHRyYW5zZm9ybShrcGwgPSBtcGcgJT4lIG11bHRpcGx5X2J5KDAuNDI1MSkpICUtPiUNCiAgYyhjeWwsIG1wZywgLi4ucmVzdCkNCmN5bA0KYGBg