Vector(广义向量)
Atomic Vector, Matrix, List and Dataframe
Humoon
2022-06-19
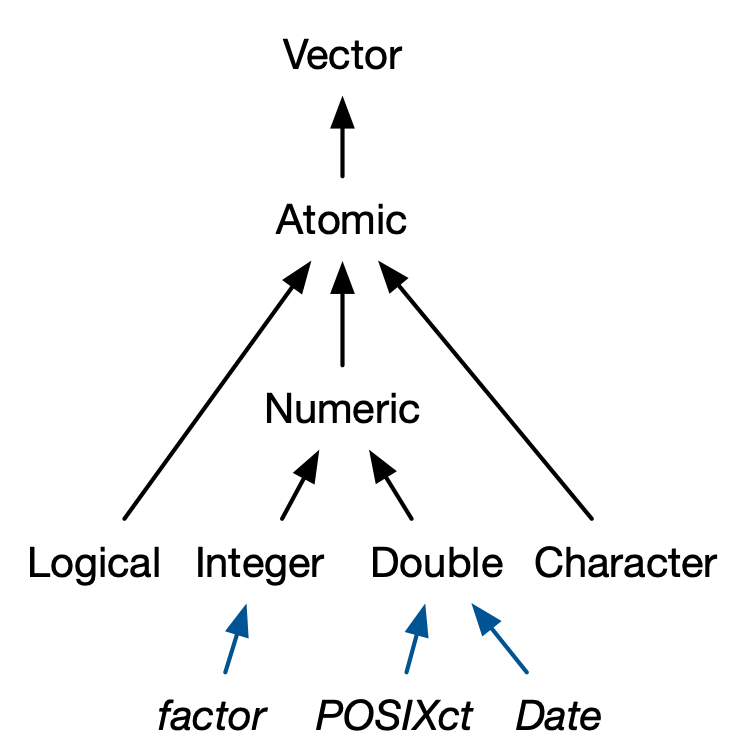
Vector 的分类
- atomic vector, matrix, array 都要求单一数据类型 (homogeneous data
type),根基是 atomic vector
- atomic vector 添加维度属性可生成 matrix, array
- atomic vector 添加 class 属性可生成 factor, date 和 date-time
- list, data.frame 可以装载不同数据类型 (heterogeneous data
types),根基是 list
- 列表提高了存储的灵活性,但降低了存储和运算效率
- 数据框是一种特殊的列表
- atomic vector 和 list 可统称为 vector
data types of atomic vector
logical
TRUE/T 和
FALSE/F
一些被设定接收逻辑输入的函数也可以接收非逻辑向量,例如数值向量。此时,非逻辑向量会被强制转换成逻辑向量:非零数值会被强制转换成 TRUE,只有 0 会被强制转换成 FALSE;字符串不能被强制转换成逻辑值,会报错。
numeric
统称数值型
- 整数,integer,形如
2L - 双精度浮点数,double
- 三种特殊情况:Inf, -Inf, NaN.
- 只要表达式中有正负无穷的项出现,结果就很可能为 Inf, -Inf, NaN
exp(1000) # R 中数字的上限为 1.8*10^38,超过这个规模就会出现 Inf #> [1] Inf-10 / 0 # -Inf 负无穷#> [1] -Infexp(1000) / exp(990) # NaN, not a number#> [1] NaNcharactor
字符串
complex
复数,形如 1+2i
空值 NULL 和缺失值 NA
NULL,零长向量,一般表示参数未被赋值,以及函数没有明确返回值时的返回。所属类、数据类型均为
“NULL”
NA,长度为 1
的逻辑向量,表示数据(元素)的缺失值。所属类、数据类型均为 “logical”
判断 NULL 和 NA 不能用 ==,只能用 is.na()
和 is.null()
a <- NULL
a # 注意控制台的输出没有 [1],长度连1都没有#> NULLlength(a)#> [1] 0class(a)#> [1] "NULL"typeof(a)#> [1] "NULL"a == NULL # 返回长度为0的向量,既不是 TRUE 也不是 FALSE#> logical(0)is.na(a)#> logical(0)b <- NA
b#> [1] NAlength(b)#> [1] 1class(b)#> [1] "logical"typeof(b)#> [1] "logical"b == NA # NA 进行任何运算都返回 NA#> [1] NAis.null(b)#> [1] FALSE查看 data type
typeof()
- vector、matrix 返回其中元素的 data type
- list、data.frame 返回 “list”
combine data
组合(combine,
一般使用c(..., use.names = TRUE))不同数据类型的向量或列表时,会强制转换为兼容所有元素的、更灵活的数据类型
一般顺序为:logical<integer<numeric<complex<character<list
a <- 1:2
b <- letters[1:2]
c(a, b)#> [1] "1" "2" "a" "b"l4 <- list(list(1, 2), c(3, 4))
l5 <- c(list(1, 2), c(3, 4))
str(l4)#> List of 2
#> $ :List of 2
#> ..$ : num 1
#> ..$ : num 2
#> $ : num [1:2] 3 4str(l5)#> List of 4
#> $ : num 1
#> $ : num 2
#> $ : num 3
#> $ : num 4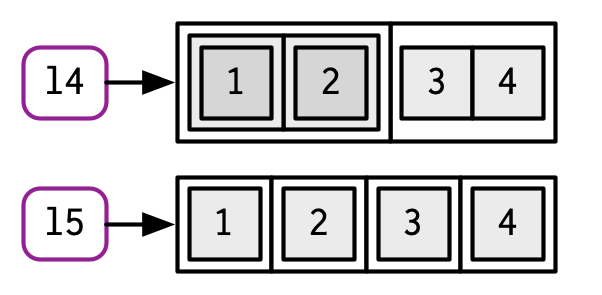
attributes
属性即作为 metadata 的键值对,附加到对象上
常用属性
- 长度,,
length()- vector、matrix 返回其中元素的个数
- list 返回键值对个数
- 数据框返回列数,因为每列(列名:值向量)是 list 的一个键值对
- 矩阵、数组和数据框的维度,
dim()- dim(vector) 不是1, 而是 NULL
- names,给每个元素一个 name 的数值向量
names()[<-]/setNames()获取/设定 names 属性,设置为 NULL 可删除 names 属性unname()去掉 names 属性(该语句也会生成一个新变量)- 从源代码可知,
setNames()和unname()是为了配合管道而设计的语法糖,内部调用的还是names()<-
处理函数
attr(x, 'a')[<-]get and modify 属性attributes(x)get 全部属性structure(.Data = x, attr1 = values1, attr2 = values2, ...)整体设置全部属性。但要注意:该语句会生成一个新变量。
attr(a, "roman_index") <- c("I", "II")
a#> [1] 1 2
#> attr(,"roman_index")
#> [1] "I" "II"attr(a, "roman_index") <- NULL
a#> [1] 1 2a <- structure(.Data = a, roman_index = c("I", "II"))
a#> [1] 1 2
#> attr(,"roman_index")
#> [1] "I" "II"names(a) <- b
attributes(a)#> $roman_index
#> [1] "I" "II"
#>
#> $names
#> [1] "a" "b"str(a)#> Named int [1:2] 1 2
#> - attr(*, "roman_index")= chr [1:2] "I" "II"
#> - attr(*, "names")= chr [1:2] "a" "b"a#> a b
#> 1 2
#> attr(,"roman_index")
#> [1] "I" "II"unname(a)#> [1] 1 2
#> attr(,"roman_index")
#> [1] "I" "II"a#> a b
#> 1 2
#> attr(,"roman_index")
#> [1] "I" "II"a <- unname(a)
a#> [1] 1 2
#> attr(,"roman_index")
#> [1] "I" "II"class 属性与 S3 对象
添加 class 属性后,对象将被转换为 S3 对象,传递给泛型函数时将具有独特的行为
Factor
x <- factor(c('a', 'b', 'b', 'a'))
x#> [1] a b b a
#> Levels: a btypeof(x)#> [1] "integer"attributes(x)#> $levels
#> [1] "a" "b"
#>
#> $class
#> [1] "factor"table(x)#> x
#> a b
#> 2 2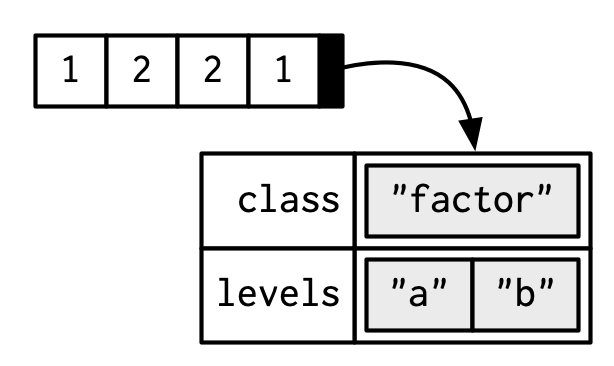
Date
class 属性:Date
today <- Sys.Date()
typeof(today)#> [1] "double"attributes(today)#> $class
#> [1] "Date"unclass(today) # 从1970年1月1日算起#> [1] 19114Date-time
class 属性:POSIXct
now_ct <- as.POSIXct("2018-08-01 22:00", tz = "UTC")
now_ct#> [1] "2018-08-01 22:00:00 UTC"typeof(now_ct)#> [1] "double"attributes(now_ct)#> $class
#> [1] "POSIXct" "POSIXt"
#>
#> $tzone
#> [1] "UTC"unclass(now_ct) # 从1970年1月1日算起的秒数#> [1] 1533160800
#> attr(,"tzone")
#> [1] "UTC"structure(now_ct, tzone = "Asia/Tokyo")#> [1] "2018-08-02 07:00:00 JST"structure(now_ct, tzone = "America/New_York")#> [1] "2018-08-01 18:00:00 EDT"structure(now_ct, tzone = "Australia/Lord_Howe")#> [1] "2018-08-02 08:30:00 +1030"structure(now_ct, tzone = "Europe/Paris")#> [1] "2018-08-02 CEST"Duration
class 属性:difftime
one_week_1 <- as.difftime(1, units = "weeks")
one_week_1#> Time difference of 1 weekstypeof(one_week_1)#> [1] "double"attributes(one_week_1)#> $class
#> [1] "difftime"
#>
#> $units
#> [1] "weeks"one_week_2 <- as.difftime(7, units = "days")
one_week_2#> Time difference of 7 daystypeof(one_week_2)#> [1] "double"attributes(one_week_2)#> $class
#> [1] "difftime"
#>
#> $units
#> [1] "days"Atomic Vector
注意
- R中无标量,标量被默认为长度为1的向量,所以在控制台显示一个数时,前面仍会有表示向量维度的
[1] - R中的向量默认为列向量,不存在行向量。对列向量转置,得到的是一个\(1\times n\)的矩阵
- R中的基础运算都是向量化的
Create
vector()
vector(mode = 'double', length = N),生成长度为 N 的空向量- 参数 mode 可以为 “integer”/“double”/“numeric”/“logical”/“character” 等,为 “list” 则生成列表
- 每项的值为
0/FALSE/""/NULL(生成列表时)
- 对于特定数据类型的向量,可以简写为:
numeric(N),logical(N),character(N)
全 1
向量的写法为vector('numeric', N) + 1或numeric(N) + 1,比
rep(1, N) 的可读性更好
y <- numeric(6) + 1
y#> [1] 1 1 1 1 1 1z <- logical(7)
z#> [1] FALSE FALSE FALSE FALSE FALSE FALSE FALSEw <- character(2)
w#> [1] "" ""w <- c(w, "a")
w#> [1] "" "" "a"c()
组合向量(将多个单元素向量和多元素向量连接起来构成一个向量),其他语言一般用[]
c() 中即使嵌套,也会被自动展开为 atomic vector
c(1, 2, c(3, 4, 5:7))#> [1] 1 2 3 4 5 6 7create 向量时可以命名
x <- c(a = 1, b = 2, c = 3)
x#> a b c
#> 1 2 3str(x) # 可见属性 names 保存着元素的名称#> Named num [1:3] 1 2 3
#> - attr(*, "names")= chr [1:3] "a" "b" "c"m:n
连续整数向量,类型为 integer vector
typeof(1:3)#> [1] "integer"seq*()
seq(from, to, by=1, length.out),等差数列,给出三个参数即可seq_len(n),等价于1:nseq_along(x),一般比1:length(x)更安全- 若 x
的长度为0,
seq_along(x)会返回integer(0),而非c(1, 0)
- 若 x
的长度为0,
seq_along(LETTERS)#> [1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25
#> [26] 26rep(x, ...)
… 中的参数包括:
- times, 重复对象 x 整体的次数,一般为标量
- 该参数也可以是与 x 长度一致的向量,表示对应元素重复对应次数
- each, 对 x 中每个元素重复的次数
- length.out, 重复若干次后结果的长度
rep(1:3, times = 2)#> [1] 1 2 3 1 2 3rep(1:3, times = c(2, 4, 1))#> [1] 1 1 2 2 2 2 3rep(1:3, each = 2)#> [1] 1 1 2 2 3 3rep(1:3, length.out = 9)#> [1] 1 2 3 1 2 3 1 2 3rep(1:3, length.out = 10)#> [1] 1 2 3 1 2 3 1 2 3 1Type
class()或typeof()查看类型is.*()判断类型- 可以使用
is.logical(),is.integer(),is.double(),is.character() - 尽量不要使用
is.vector(),is.atomic(),is.numeric() as.*()转换类型- 尽量不要使用
as.vector()
class(1:5)#> [1] "integer"class(c(T, F, T))#> [1] "logical"is.character(c("h", "e", "l", "l", "o"))#> [1] TRUEas.character(1:5)#> [1] "1" "2" "3" "4" "5"strings <- c("1", "2", "3")
try(strings + 10)#> Error in strings + 10 : non-numeric argument to binary operatortry(as.numeric(strings) + 10)#> [1] 11 12 13Size
length()
length(w)#> [1] 3Label
names()[<-] 提取/赋值
赋值为 NULL 时移除 names 属性,或通过
x <- unname(x)
Subset
选择器[]和提取器[[]]
[]为子集选择器,返回的是原数据的一个切片,不改变数据结构
[[]]为元素提取器,返回的是原数据一个长度为1的切片中装载的内容
对向量操作,[]和[[]]的差别很小;但对更复杂的数据类型,二者的差别会很明显:
str(iris) # 数据框#> 'data.frame': 150 obs. of 5 variables:
#> $ Sepal.Length: num 5.1 4.9 4.7 4.6 5 5.4 4.6 5 4.4 4.9 ...
#> $ Sepal.Width : num 3.5 3 3.2 3.1 3.6 3.9 3.4 3.4 2.9 3.1 ...
#> $ Petal.Length: num 1.4 1.4 1.3 1.5 1.4 1.7 1.4 1.5 1.4 1.5 ...
#> $ Petal.Width : num 0.2 0.2 0.2 0.2 0.2 0.4 0.3 0.2 0.2 0.1 ...
#> $ Species : Factor w/ 3 levels "setosa","versicolor",..: 1 1 1 1 1 1 1 1 1 1 ...str(iris[1]) # 只含一个变量的数据框#> 'data.frame': 150 obs. of 1 variable:
#> $ Sepal.Length: num 5.1 4.9 4.7 4.6 5 5.4 4.6 5 4.4 4.9 ...str(iris[[1]]) # 向量#> num [1:150] 5.1 4.9 4.7 4.6 5 5.4 4.6 5 4.4 4.9 ...[]选取的三种方式
- 位置 index,
x[4]; x[-2:-4]; x[c(1, 3)]- 其中正数表示选择,复数表示剔除,
[]中不能同时有正数和负数 - index 为 0 将返回长度为 0 的向量
- index 为空表示保留这一维度的所有元素
- 其中正数表示选择,复数表示剔除,
- logical vector, 选出相应位置为 TRUE 的元素
- 通过 condition
获得逻辑向量,
x[x == 10]; x[x %in% c(1, 2, 5)]
- 通过 condition
获得逻辑向量,
- names 属性,
x["apple"]
x <- c(1, 2, 3, 4, 5, 6, 7)
names(x) <- letters[1:7]
# index
x[3:5] # x向量中的第3-5个元素#> c d e
#> 3 4 5x[c(1, 4)] <- c(100, 400) # 第1个和第4个元素
x#> a b c d e f g
#> 100 2 3 400 5 6 7x[6:9] # 超出index时返回 NA#> f g <NA> <NA>
#> 6 7 NA NAx#> a b c d e f g
#> 100 2 3 400 5 6 7x[10] <- 10 # 对一个并不存在的元素重新赋值,将自动用 NA 填充未被指定的位置
x#> a b c d e f g
#> 100 2 3 400 5 6 7 NA NA 10x[-2] # 除了第二个以外的元素#> a c d e f g
#> 100 3 400 5 6 7 NA NA 10x[-2:-4] # 等价于 x[c(-2, -3, -4)],即去掉第2、3、4个元素#> a e f g
#> 100 5 6 7 NA NA 10# condition
x[x %in% c(1, 2, 5)]#> b e
#> 2 5# names
x["e"]#> e
#> 5x[c("e", "j")] # 访问不存在的name,返回 NA#> e <NA>
#> 5 NAApplication: lookup table
x <- c("m", "f", "u", "f", "f", "m", "m")
lookup <- c(m = "Male", f = "Female", u = NA) # 键值对
lookup[x] %>% unname()#> [1] "Male" "Female" NA "Female" "Female" "Male" "Male"[[]]忽略 names
[[]]
只能提取一个元素,其中也不能出现负整数或访问不存在的元素(下标越界)
x <- c(a = 1, b = 2, c = 3)
x["a"]#> a
#> 1x[["a"]]#> [1] 1try(x[[-1]])#> Error in x[[-1]] : invalid negative subscript in get1index <real>try(x[[4]])#> Error in x[[4]] : subscript out of boundstry(x[["d"]])#> Error in x[["d"]] : subscript out of bounds下标越界
返回 NA
Index
which*
which(逻辑表达式)which.min()which.max()
x#> a b c
#> 1 2 3which.max(x)#> c
#> 3which.min(x)#> a
#> 1which(x == 2)#> b
#> 2which(x > 4)#> named integer(0)*match
match(vector1, vector2)返回第一个向量中各元素在第二个向量中的位置序列,每一个都从头开始匹配,只要匹配到就结束。pmatch(vector1, vector2),若第一个向量中某元素在第二个向量中匹配上了,则认为第二个向量中相应元素已被占用,再匹配第一个向量中的下一个元素时,跳过第二个向量中曾被匹配过的元素。
match(rep(1, 3), rep(1, 5))#> [1] 1 1 1pmatch(rep(1, 3), rep(1, 5))#> [1] 1 2 3Operation
R 对向量的操作都要在原向量的拷贝上进行,不改变原向量(只有直接赋值能改变原向量)。好处是安全,坏处是慢。
增删改
append()返回插入元素后的拷贝. 注意,R 中一般不直接修改原对象,所以如果要保留这个操作,一定要记得赋值给原变量。x <- x[-index]删除选集replace()批量替换
x <- c(1, 2, 3, 4, 5, 7)
x <- replace(x, c(3, 4), c(5, 5)) # 替换:将x向量中第3个和第4个元素替换为5
x#> [1] 1 2 5 5 5 7append(x, 100, after = 2)#> [1] 1 2 100 5 5 5 7x#> [1] 1 2 5 5 5 7a <- c(0, 0, 1, 2, 0, 3) # 删除零值项
b <- which(a == 0)
b#> [1] 1 2 5a <- a[-b]
a#> [1] 1 2 3Sort
rank(x)返回x中各元素相对大小的排序(默认升序)order(x)返回按照递增/递减的次序重排列x后,新序列各元素在原序列x中的位置sort(x)返回排序后的向量,对于数字默认升序,对于字符串默认字典顺序rev(x)逆序排列
x#> [1] 1 2 5 5 5 7rank(x)#> [1] 1 2 4 4 4 6sort(x) # 默认升序排序#> [1] 1 2 5 5 5 7x#> [1] 1 2 5 5 5 7rev(x) # 逆序#> [1] 7 5 5 5 2 1x#> [1] 1 2 5 5 5 7去重、偏移、差分
unique()去重lead(x, n=1),lag(x, n=1)偏移,返回一个序列的领先序列和滞后序列diff(x, lag=1)差分,lag 用以指定滞后几项。默认的 lag 值为 1
unique(x)#> [1] 1 2 5 7x#> [1] 1 2 5 5 5 7lead(x, 2)#> [1] 5 5 5 7 NA NAx#> [1] 1 2 5 5 5 7diff(x)#> [1] 1 3 0 0 2x#> [1] 1 2 5 5 5 7统计条件频数
sum(vector中元素要符合的条件)
# 1 的个数
vector <- c(1, -1, 2, -2, 3, 4, 0, 2, 3, 4, 1, 1)
sum(vector == 1)#> [1] 3交叉循环遍历
expand.grid(..., stringsAsFactors = TRUE),…参数为若干个向量,比如数值向量
x 和 y,效果为对二元数值对 (x, y)
所有可能取值的遍历(返回数据框)。
若 … 为字符串向量,最好将 stringsAsFactors 参数设置为 TRUE
x <- 1:3
y <- letters[1:3]
z <- 1:3
expand.grid(x, y)#> Var1 Var2
#> 1 1 a
#> 2 2 a
#> 3 3 a
#> 4 1 b
#> 5 2 b
#> 6 3 b
#> 7 1 c
#> 8 2 c
#> 9 3 cexpand.grid(x, z)#> Var1 Var2
#> 1 1 1
#> 2 2 1
#> 3 3 1
#> 4 1 2
#> 5 2 2
#> 6 3 2
#> 7 1 3
#> 8 2 3
#> 9 3 3算数运算
向量化运算:对应元素分别运算,较短的向量自动循环直至长度与较长向量匹配
向量元素的 names 不参与运算,但运算符左侧向量的 names 会保留在结果中,右侧向量的 names 被忽略
## 四则运算(+-*/)、幂(^)、取整(%/%)、取余(%%)
1 / (1:6) # 自动将标量(长度为 1 的向量)扩展为长度为 6 的向量后再运算#> [1] 1.0000000 0.5000000 0.3333333 0.2500000 0.2000000 0.16666671 / matrix(1:4, nrow = 2) # 自动将标量扩展为对应维度的矩阵后再运算#> [,1] [,2]
#> [1,] 1.0 0.3333333
#> [2,] 0.5 0.2500000x <- 1:5
y <- 2:6
x * y # 哈达马积#> [1] 2 6 12 20 30## 向量内积(以下写法等价)
1 * 2 + 2 * 3 + 3 * 4 + 4 * 5 + 5 * 6#> [1] 70sum(x * y)#> [1] 70t(x) %*% y # 利用矩阵乘法,注意 R 中向量默认为列向量#> [,1]
#> [1,] 70crossprod(x, y) # 利用矩阵乘法,得到一个 1*1 矩阵#> [,1]
#> [1,] 70## 向量外积(以下写法等价)
x %*% t(y)#> [,1] [,2] [,3] [,4] [,5]
#> [1,] 2 3 4 5 6
#> [2,] 4 6 8 10 12
#> [3,] 6 9 12 15 18
#> [4,] 8 12 16 20 24
#> [5,] 10 15 20 25 30x %o% y#> [,1] [,2] [,3] [,4] [,5]
#> [1,] 2 3 4 5 6
#> [2,] 4 6 8 10 12
#> [3,] 6 9 12 15 18
#> [4,] 8 12 16 20 24
#> [5,] 10 15 20 25 30kronecker(x, t(y)) # 克罗内克积#> [,1] [,2] [,3] [,4] [,5]
#> [1,] 2 3 4 5 6
#> [2,] 4 6 8 10 12
#> [3,] 6 9 12 15 18
#> [4,] 8 12 16 20 24
#> [5,] 10 15 20 25 30outer(x, y)#> [,1] [,2] [,3] [,4] [,5]
#> [1,] 2 3 4 5 6
#> [2,] 4 6 8 10 12
#> [3,] 6 9 12 15 18
#> [4,] 8 12 16 20 24
#> [5,] 10 15 20 25 30tcrossprod(x, y)#> [,1] [,2] [,3] [,4] [,5]
#> [1,] 2 3 4 5 6
#> [2,] 4 6 8 10 12
#> [3,] 6 9 12 15 18
#> [4,] 8 12 16 20 24
#> [5,] 10 15 20 25 30逻辑运算
x <- 1:6
x < 4#> [1] TRUE TRUE TRUE FALSE FALSE FALSEall(x > 5) # 一个向量的所有元素是否满足某条件#> [1] FALSEany(x > 5) # 一个向量的部分元素是否满足某条件#> [1] TRUEmatrix(x, 2, byrow = T) < 4#> [,1] [,2] [,3]
#> [1,] TRUE TRUE TRUE
#> [2,] FALSE FALSE FALSE集合运算
intersect(c(1, 2, 3, 3, 12, 4, 123, 12), c(1, 2, 3)) # 交#> [1] 1 2 3union(c("狗熊会", "聚数据英才"), c("狗熊会", "助产业振兴")) # 并#> [1] "狗熊会" "聚数据英才" "助产业振兴"setdiff(10:2, 5:3) # 差#> [1] 10 9 8 7 6 2Matrix
Create
向量转化为矩阵
matrix(vector, nrow, ncol, byrow = FALSE, dimnames = NULL),默认按列填充矩阵,byrow 设为 TRUE 可按行为向量添加维度属性
dim(vector) <- c(nrow,ncol)
## 生成 3*3 的全 1 矩阵
# 第一种
rep(1, 9) %>% matrix(nrow = 3)#> [,1] [,2] [,3]
#> [1,] 1 1 1
#> [2,] 1 1 1
#> [3,] 1 1 1# 第二种
x <- rep(1, 9)
dim(x) <- c(3, 3)
x # 这种方式改变了变量 x 的值,不是很推荐,还是第一种更好#> [,1] [,2] [,3]
#> [1,] 1 1 1
#> [2,] 1 1 1
#> [3,] 1 1 1diag()
diag(x = 1, nrow, ncol, names = TRUE)- x 为标量或向量时,
diag()表示根据对角元 create 矩阵 - x 为矩阵时,
diag()为提取对角元,返回向量 - x 为标量且只有这一个参数时,返回 \(n\) 阶单位阵 \(I_n\)
- x 为标量或向量时,
diag(x) <- value, value 可以是标量或向量
diag(4) # n 阶单位阵#> [,1] [,2] [,3] [,4]
#> [1,] 1 0 0 0
#> [2,] 0 1 0 0
#> [3,] 0 0 1 0
#> [4,] 0 0 0 1diag(0, 4) # 全 0 四阶方阵#> [,1] [,2] [,3] [,4]
#> [1,] 0 0 0 0
#> [2,] 0 0 0 0
#> [3,] 0 0 0 0
#> [4,] 0 0 0 0diag(10, 3, 4) # nrow 和 ncol 可以不相等#> [,1] [,2] [,3] [,4]
#> [1,] 10 0 0 0
#> [2,] 0 10 0 0
#> [3,] 0 0 10 0diag(0, 3, 4) # 任意 size 的全 0 矩阵#> [,1] [,2] [,3] [,4]
#> [1,] 0 0 0 0
#> [2,] 0 0 0 0
#> [3,] 0 0 0 0diag(0, 3, 4) + 1 # 任意 size 的全 1 矩阵#> [,1] [,2] [,3] [,4]
#> [1,] 1 1 1 1
#> [2,] 1 1 1 1
#> [3,] 1 1 1 1matrix(numeric(12), nrow = 3) + 1 # 任意 size 全 1 矩阵的另一种写法#> [,1] [,2] [,3] [,4]
#> [1,] 1 1 1 1
#> [2,] 1 1 1 1
#> [3,] 1 1 1 1x <- diag(1:5) # create 对角矩阵
x#> [,1] [,2] [,3] [,4] [,5]
#> [1,] 1 0 0 0 0
#> [2,] 0 2 0 0 0
#> [3,] 0 0 3 0 0
#> [4,] 0 0 0 4 0
#> [5,] 0 0 0 0 5diag(x) <- 2
x#> [,1] [,2] [,3] [,4] [,5]
#> [1,] 2 0 0 0 0
#> [2,] 0 2 0 0 0
#> [3,] 0 0 2 0 0
#> [4,] 0 0 0 2 0
#> [5,] 0 0 0 0 2diag(x) <- letters[1:5]
x#> [,1] [,2] [,3] [,4] [,5]
#> [1,] "a" "0" "0" "0" "0"
#> [2,] "0" "b" "0" "0" "0"
#> [3,] "0" "0" "c" "0" "0"
#> [4,] "0" "0" "0" "d" "0"
#> [5,] "0" "0" "0" "0" "e"矩阵转化为向量
as.vector() 按照一列一列地顺序将矩阵展开为向量
Type
is.matrix()判断as.matrix(x)转换,x为数据框时,自动转换为兼容所有元素的、更灵活的数据类型data.matrix(x)转换数据框,自动将所有元素转换为数字
Size
nrow(A), ncol(A) 作用于向量时返回
NULL,其变体 NROW(), NCOL()
可作用于向量(将其视为 \(n\times1\)
矩阵) dim(A),返回长度为 2 的向量 length(A)
返回矩阵元素的个数(矩阵展开为向量的 size)
Label
在默认情况下,创建矩阵时不会自动分配行名和列名。当不同的行列有不同的含义时, 为其命名就显得必要且直观。
创建矩阵时为行列命名
matrix() 的 dimnames 参数,取值为 list(row_name_vector,
col_name_vector)
创建矩阵后为行列命名
rownames(A) [<-] 提取/赋值
colnames(A) [<-] 提取/赋值
Subset
二维选择器
[行选择器, 列选择器] 每个选择器都可以是index、condition
和 name;若一个维度的参数空缺,则该维度的所有值都会被选出来
矩阵的[]选择器会返回维度尽可能低的结果,因此A[2, ]返回的是向量而非\(1\times
n\)的矩阵。如果不想降维(即使选择一列也要保持 class
属性为矩阵),需要设置 drop 参数
[行选择器, 列选择器, drop = FALSE]
A <- matrix(1:16, 4)
A[2, ] # A的第2行#> [1] 2 6 10 14A[, -2] # A排除第2列#> [,1] [,2] [,3]
#> [1,] 1 9 13
#> [2,] 2 10 14
#> [3,] 3 11 15
#> [4,] 4 12 16A[3, 2] # A的第3行第2列#> [1] 7A[3, c(2, 4)] # A的第3行第2列和第4列#> [1] 7 15一维选择器
矩阵本质上是一个向量,所以适用向量的一维选择器
A <- matrix(1:9, 3)
A[A > 3]#> [1] 4 5 6 7 8 9矩阵选择器
使用矩阵作为选择器,矩阵的每一行提供多维 index,选择一个元素;列数决定选择元素的个数
vals <- outer(1:5, 1:5, FUN = "paste", sep = ",")
vals#> [,1] [,2] [,3] [,4] [,5]
#> [1,] "1,1" "1,2" "1,3" "1,4" "1,5"
#> [2,] "2,1" "2,2" "2,3" "2,4" "2,5"
#> [3,] "3,1" "3,2" "3,3" "3,4" "3,5"
#> [4,] "4,1" "4,2" "4,3" "4,4" "4,5"
#> [5,] "5,1" "5,2" "5,3" "5,4" "5,5"select <- matrix(ncol = 2, byrow = TRUE, c(
1, 1,
3, 1,
2, 4
))
select#> [,1] [,2]
#> [1,] 1 1
#> [2,] 3 1
#> [3,] 2 4vals[select]#> [1] "1,1" "3,1" "2,4"Index
row(A), col(A)
返回两个矩阵,元素分别为行列下标。
A <- matrix(1:16, 4)
A#> [,1] [,2] [,3] [,4]
#> [1,] 1 5 9 13
#> [2,] 2 6 10 14
#> [3,] 3 7 11 15
#> [4,] 4 8 12 16row(A)#> [,1] [,2] [,3] [,4]
#> [1,] 1 1 1 1
#> [2,] 2 2 2 2
#> [3,] 3 3 3 3
#> [4,] 4 4 4 4col(A)#> [,1] [,2] [,3] [,4]
#> [1,] 1 2 3 4
#> [2,] 1 2 3 4
#> [3,] 1 2 3 4
#> [4,] 1 2 3 4# 提取下三角矩阵算法
A[row(A) < col(A)] <- 0
A#> [,1] [,2] [,3] [,4]
#> [1,] 1 0 0 0
#> [2,] 2 6 0 0
#> [3,] 3 7 11 0
#> [4,] 4 8 12 16Operation
转置 t(A)
向量没有维度属性,不是矩阵。要把向量转化为 \(1 \times n\) 和 \(n \times 1\) 的矩阵,可以用
dim(),也可以用 t(),
as.matrix()
x <- 1:6
as.matrix(x) # 最直观#> [,1]
#> [1,] 1
#> [2,] 2
#> [3,] 3
#> [4,] 4
#> [5,] 5
#> [6,] 6x %>% `dim<-`(c(6, 1))#> [,1]
#> [1,] 1
#> [2,] 2
#> [3,] 3
#> [4,] 4
#> [5,] 5
#> [6,] 6t(t(x))#> [,1]
#> [1,] 1
#> [2,] 2
#> [3,] 3
#> [4,] 4
#> [5,] 5
#> [6,] 6x %>% `dim<-`(c(1, 6))#> [,1] [,2] [,3] [,4] [,5] [,6]
#> [1,] 1 2 3 4 5 6t(x)#> [,1] [,2] [,3] [,4] [,5] [,6]
#> [1,] 1 2 3 4 5 6对数据框使用 t(),会自动将其转换为矩阵
矩阵乘法
A%*%B- 一个例外:若 A 和 B 均为列向量,则运算时自动对 A 转置1,执行
t(A)%*%B,返回 A 与 B 的内积 crossprod(A, B)是t(A) %*% B的简写tcrossprod(A, B)是A %*% t(B)的简写
- 一个例外:若 A 和 B 均为列向量,则运算时自动对 A 转置1,执行
*, 哈达马积kronecker(), 克罗内克积
# 矩阵乘法
m1 <- matrix(1:9, 3)
m1 %*% m1#> [,1] [,2] [,3]
#> [1,] 30 66 102
#> [2,] 36 81 126
#> [3,] 42 96 150对角元素
diag(A) 返回对角元素组成的向量
矩阵的逆;线性方程组的解
solve(A, B), 返回A %*% X = B的解。solve(A), 返回矩阵A的逆,即Solve(A, I)
特征值和特征向量
A.eigen <- eigen(A, symmetric=T)
行列式
det(A)
提取上、下三角矩阵
lower.tri(A,diag=T/F)和upper.tri(A,diag=T/F),这两个函数返回逻辑矩阵
A <- matrix(1:16, 4)
A#> [,1] [,2] [,3] [,4]
#> [1,] 1 5 9 13
#> [2,] 2 6 10 14
#> [3,] 3 7 11 15
#> [4,] 4 8 12 16A[lower.tri(A)] <- 0 # A[lower.tri(A)] 为一维选择器,返回向量而非矩阵
A#> [,1] [,2] [,3] [,4]
#> [1,] 1 5 9 13
#> [2,] 0 6 10 14
#> [3,] 0 0 11 15
#> [4,] 0 0 0 16正定矩阵的Choleskey分解
chol(A)
即返回满足 \(A=P{^T}P\) 的P,其中P为上三角矩阵
矩阵合并
rbind(), cbind()
rbind(A, B)
cbind(A, B)
dplyr::bind_rows(A, B)
dplyr::bind_cols(A, B)对行、列分别操作
apply(matrix, 1, f)将行依次传递给 fapply(matrix, 2, f)将列依次传递给 frowSums()rowMeans()colSums()colMeans()
A <- matrix(1:16, 4)
A#> [,1] [,2] [,3] [,4]
#> [1,] 1 5 9 13
#> [2,] 2 6 10 14
#> [3,] 3 7 11 15
#> [4,] 4 8 12 16rowSums(A)#> [1] 28 32 36 40apply(A, 1, sum)#> [1] 28 32 36 40colMeans(A)#> [1] 2.5 6.5 10.5 14.5apply(A, 2, mean)#> [1] 2.5 6.5 10.5 14.5Array
张量,或更高维度的向量
Create
z<-array(vector, dimensions, dimnames = list(v1, v2, v3, ...))
Label
dimnames() [<-] 提取/赋值
z <- array(1:24, dim = c(2, 3, 4), dimnames = list(c("r1", "r2"), c("c1", "c2", "c3"), c("p1", "p2", "p3", "p4")))
z#> , , p1
#>
#> c1 c2 c3
#> r1 1 3 5
#> r2 2 4 6
#>
#> , , p2
#>
#> c1 c2 c3
#> r1 7 9 11
#> r2 8 10 12
#>
#> , , p3
#>
#> c1 c2 c3
#> r1 13 15 17
#> r2 14 16 18
#>
#> , , p4
#>
#> c1 c2 c3
#> r1 19 21 23
#> r2 20 22 24dimnames(z)#> [[1]]
#> [1] "r1" "r2"
#>
#> [[2]]
#> [1] "c1" "c2" "c3"
#>
#> [[3]]
#> [1] "p1" "p2" "p3" "p4"Subset
[第1维选择器, 第2维选择器, 第3维选择器, ...]
List
list 逻辑上是一组有序键值对的集合(就像 JS 中的对象)
但实现上是广义向量(作为 values)附加了 index 或 names 属性(作为 keys)
Create
直接定义列表内容
list(name1 = value1, name2 = value2, ...),可以省略
names
长度为 N 的空列表
vector(mode = 'list', length = N)
R 中的 vector 天然体现着向量的“广义”
Type
is.list()判断as.list()转换as.vector()对list无效,因为 list 是广义向量,“vector”包含了”list”
unlist()将列表强制转换为向量。由于规则过于复杂,最好不要使用该函数- 按分量顺序依次排列,强制不再嵌套!
- 自动保证同样的数据类型。比如,强制转换混合了数值和文本的列表,会得到字符串向量
l <- list(1, 2, 3)
l#> [[1]]
#> [1] 1
#>
#> [[2]]
#> [1] 2
#>
#> [[3]]
#> [1] 3as.vector(l)#> [[1]]
#> [1] 1
#>
#> [[2]]
#> [1] 2
#>
#> [[3]]
#> [1] 3as.integer(l)#> [1] 1 2 3unlist(l)#> [1] 1 2 3Size
dim(list)<-可以创建列表矩阵
l <- list(1:3, "a", TRUE, 1.0)
dim(l) <- c(2, 2)
l#> [,1] [,2]
#> [1,] integer,3 TRUE
#> [2,] "a" 1l[[1, 1]]#> [1] 1 2 3Label
names(list) [<-] 提取/赋值
赋值为 NULL 时移除 names 属性,或通过
x <- unname(x)
Subset
第一种语法,用[]符号,里面可以是 index/condition/key
第二种语法,用 `[`() 或 magrittr::extract()函数
l <- list("a", 2, TRUE)
l[1]#> [[1]]
#> [1] "a"`[`(l, 1)#> [[1]]
#> [1] "a"magrittr::extract(l, 1)#> [[1]]
#> [1] "a"下标越界时,返回 NULL
Extract
- 第一种语法,用
[[]]符号,里面可以是 index/condition(logical vector)/key - 第二种语法,用
list$key,是list[['key']]的语法糖- 若 “key” 储存在一个变量 var
中,
df$var等价于df[["var"]],是无效的,此时只有df[[var]]才能生效。所以,df[["key"]]总是比df$key更保险一些 $能部分匹配变量名,而[[]]总是完全精准地匹配
- 若 “key” 储存在一个变量 var
中,
- 第三种语法,用 `[[`() 或
magrittr::extract2()函数 - 第四种语法,用
purrr::pluck(.x, ..., .default = NULL)或purrr::chuck(.x, ...)- …可以是用逗号间隔的多个name/index,适用于对深度嵌套列表(读取 JSON 文件时很常见)的提取
- 要搜索的元素不存在时,pluck() 默认返回 NULL,而 chuck() 会抛出错误
l[[1]]#> [1] "a"`[[`(l, 1)#> [1] "a"magrittr::extract2(l, 1)#> [1] "a"x <- list(
a = list(1, 2, 3),
b = list(3, 4, 5)
)
purrr::pluck(x, "a", 1)#> [1] 1purrr::pluck(x, "c", 1)#> NULLpurrr::pluck(x, "c", 1, .default = NA)#> [1] NAOperation
改变元素
对相应元素直接赋值
删除元素
赋值为 NULL 即为删除
添加元素
第一种语法,对新元素赋值。
# 添加元素的最佳写法,无需知道 index
l <- list(...)
l[[length(l) + 1]] <- new_element第二种语法,append(list, value, after = length(list)),默认加到列表的末尾。但若插入的元素本身是一个列表(很多对象本质上都是一个列表),则会破坏层级结构,将所有的元素依次插入到前一个列表。所以若要保存列表的层级结构,还是第一种语法更保险。
l[[4]] <- data.table(x = 1, y = 2)
l$z <- c("one", "two", "three")
l#> [[1]]
#> [1] "a"
#>
#> [[2]]
#> [1] 2
#>
#> [[3]]
#> [1] TRUE
#>
#> [[4]]
#> x y
#> 1: 1 2
#>
#> $z
#> [1] "one" "two" "three"l <- append(l, 6)
l#> [[1]]
#> [1] "a"
#>
#> [[2]]
#> [1] 2
#>
#> [[3]]
#> [1] TRUE
#>
#> [[4]]
#> x y
#> 1: 1 2
#>
#> $z
#> [1] "one" "two" "three"
#>
#> [[6]]
#> [1] 6l <- append(l, list(7, 8))
l#> [[1]]
#> [1] "a"
#>
#> [[2]]
#> [1] 2
#>
#> [[3]]
#> [1] TRUE
#>
#> [[4]]
#> x y
#> 1: 1 2
#>
#> $z
#> [1] "one" "two" "three"
#>
#> [[6]]
#> [1] 6
#>
#> [[7]]
#> [1] 7
#>
#> [[8]]
#> [1] 8l[[9]] <- list(9, 10)
l#> [[1]]
#> [1] "a"
#>
#> [[2]]
#> [1] 2
#>
#> [[3]]
#> [1] TRUE
#>
#> [[4]]
#> x y
#> 1: 1 2
#>
#> $z
#> [1] "one" "two" "three"
#>
#> [[6]]
#> [1] 6
#>
#> [[7]]
#> [1] 7
#>
#> [[8]]
#> [1] 8
#>
#> [[9]]
#> [[9]][[1]]
#> [1] 9
#>
#> [[9]][[2]]
#> [1] 10Data.Frame
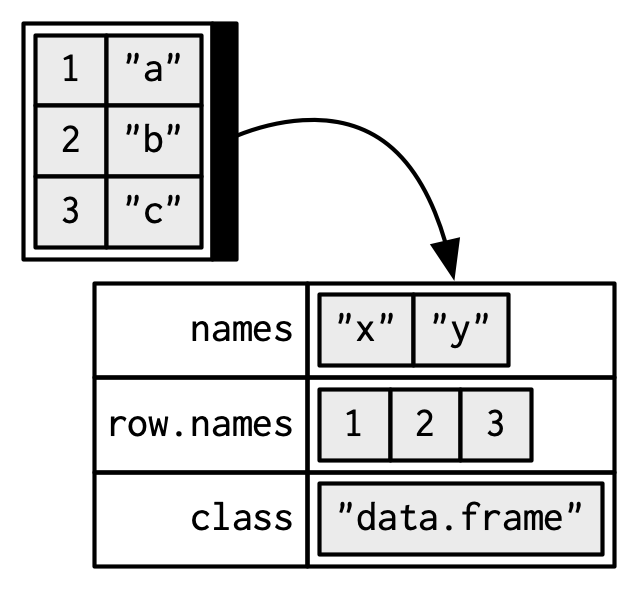
data.frame 是长度相同的列向量(此处向量是广义的,即可以是 atomic vector 或 list)组成的 List.
R 原生支持向量化操作,因此 R 操作数据框中的向量有先天优势,语法简洁。
同时,data.frame 可以像矩阵一样,以二维表方式呈现。因此,R 中操作矩阵的一些(泛型)函数兼容了 data.frame 对象,即可以像操作矩阵一样操作 data.frame
Create
data.frame(var1 = col1, var2 = col2, …, row.names = NULL, check.names = TRUE, stringsAsFactors = FALSE)
R 4.0 之前,构建R的原生数据框时,参数 stringsAsFactors 的默认值为 TRUE,字符向量默认被转换成因子(因子的 level 相比字符串节省储存空间),数据类型变为 numeric,无法再用字符串函数处理。4.0 后更改了这一默认值。
check.names 默认为 TRUE,建立数据框时会使用函数
make.names()检查变量名,将 R 不允许出现在变量名中的特殊字符转换为.,如将列名Population(before)自动转换为Population.before.- 若选 FALSE,会最大限度地保留原本的列名。但访问这些在 R 中本为非法的列时,必须用反引号将列名括起来,形如 results$`Population(before)`
list columns
# 创建数据框后添加
df <- data.frame(x = 1:3)
df$y <- list(1:2, 1:3, 1:4)
df#> x y
#> 1 1 1, 2
#> 2 2 1, 2, 3
#> 3 3 1, 2, 3, 4# 或用 I() 包裹,表示不会自动转换
data.frame(
x = 1:3,
y = I(list(1:2, 1:3, 1:4))
)#> x y
#> 1 1 1, 2
#> 2 2 1, 2, 3
#> 3 3 1, 2, 3, 4Matrix and data frame columns
虽然 R 允许将矩阵和 data frame 作为列,但最好不要这样使用,因为很多函数默认每一列都是向量,不兼容这种罕见的情况
dfm <- data.frame(
x = 1:3 * 10
)
dfm$y <- matrix(1:9, nrow = 3)
dfm$z <- data.frame(a = 3:1, b = letters[1:3], stringsAsFactors = FALSE)
str(dfm)#> 'data.frame': 3 obs. of 3 variables:
#> $ x: num 10 20 30
#> $ y: int [1:3, 1:3] 1 2 3 4 5 6 7 8 9
#> $ z:'data.frame': 3 obs. of 2 variables:
#> ..$ a: int 3 2 1
#> ..$ b: chr "a" "b" "c"dfm#> x y.1 y.2 y.3 z.a z.b
#> 1 10 1 4 7 3 a
#> 2 20 2 5 8 2 b
#> 3 30 3 6 9 1 cType
as.data.frame()将矩阵、列表强制转换为数据框- 如果矩阵已有行、列名,会在转换过程中保留
Label
适用于 matrix
的rownames()和colnames()也适用于数据框。
但rownames 不是一个好的设计,完全可以将其作为数据框的一列,尽量不要用。
a <- list(id = 1:5, lower = letters[1:5], upper = LETTERS[1:5])
class(a)#> [1] "list"colnames(a)#> NULLb <- as.data.frame(a)
class(b)#> [1] "data.frame"colnames(b)#> [1] "id" "lower" "upper"Subset
既可以用列表风格的[],也可以用矩阵风格的[rowSelector, columnSelector]
- 矩阵风格选择器的好处在于,可以灵活地筛选行
df <- data.frame(
id = 1:5,
lower = letters[1:5],
upper = LETTERS[1:5]
)
# 矩阵风格的选择器
df[df$id > 3, c(2, 3)]#> lower upper
#> 4 d D
#> 5 e E- 用矩阵风格的二维选择器时,跟矩阵一样会尽可能降维
- 如果纵向只取了一列,则返回值会自动简化为向量,而非数据框。
- 若要避免降维,保留数据框结构,可以结合两种风格的选择器,也可以增加选项
drop = FALSE。 - 最好是用 dplyr 中的函数替代选择器,用
select()时不会降维,如果希望降维再用pull()即可,语义很明晰。
## 保留数据框
df[2:3, 2, drop = FALSE]#> lower
#> 2 b
#> 3 cdf[2:3, ][2] # 混合两种选择器#> lower
#> 2 b
#> 3 cdf[2:3, ] %>% select(2)#> lower
#> 2 b
#> 3 c# 不保留数据框
df[2:3, 2]#> [1] "b" "c"df[2:3, ] %>% select(2) %>% pull()#> [1] "b" "c"subset(df, conditions, select)
函数而非操作符,便利 Pipeline 的连续操作
第一个参数为数据集,第二个参数选择符合条件的行,第三个参数select选择列,可以在列名前加’-’删除之
subset(leadership, age >= 35 | age < 24, select = c(q1, q2, q3, q4))Extract
df$colnamedf[[index]]df[["colname"]]- 矩阵风格选择器,选择一列
dplyr::pull(df, colname)
df$lower#> [1] "a" "b" "c" "d" "e"df[[2]]#> [1] "a" "b" "c" "d" "e"df[["lower"]]#> [1] "a" "b" "c" "d" "e"df[, 2]#> [1] "a" "b" "c" "d" "e"dplyr::pull(df, lower)#> [1] "a" "b" "c" "d" "e"Operation
对数据框的精细操作是 R 最核心的内容,之后单列一章说明。
增删改
类似 list、matrix,以赋值为核心。
数据框合并
rbind(), cbind()
描述统计
summary() 描述统计各列数据
summary(mtcars)#> mpg cyl disp hp
#> Min. :10.40 Min. :4.000 Min. : 71.1 Min. : 52.0
#> 1st Qu.:15.43 1st Qu.:4.000 1st Qu.:120.8 1st Qu.: 96.5
#> Median :19.20 Median :6.000 Median :196.3 Median :123.0
#> Mean :20.09 Mean :6.188 Mean :230.7 Mean :146.7
#> 3rd Qu.:22.80 3rd Qu.:8.000 3rd Qu.:326.0 3rd Qu.:180.0
#> Max. :33.90 Max. :8.000 Max. :472.0 Max. :335.0
#> drat wt qsec vs
#> Min. :2.760 Min. :1.513 Min. :14.50 Min. :0.0000
#> 1st Qu.:3.080 1st Qu.:2.581 1st Qu.:16.89 1st Qu.:0.0000
#> Median :3.695 Median :3.325 Median :17.71 Median :0.0000
#> Mean :3.597 Mean :3.217 Mean :17.85 Mean :0.4375
#> 3rd Qu.:3.920 3rd Qu.:3.610 3rd Qu.:18.90 3rd Qu.:1.0000
#> Max. :4.930 Max. :5.424 Max. :22.90 Max. :1.0000
#> am gear carb
#> Min. :0.0000 Min. :3.000 Min. :1.000
#> 1st Qu.:0.0000 1st Qu.:3.000 1st Qu.:2.000
#> Median :0.0000 Median :4.000 Median :2.000
#> Mean :0.4062 Mean :3.688 Mean :2.812
#> 3rd Qu.:1.0000 3rd Qu.:4.000 3rd Qu.:4.000
#> Max. :1.0000 Max. :5.000 Max. :8.000tibble
data.frame 的优化替代类型,但已有更好的替代类型 data.table,所以 tibble 不再重要
tibble 打印时
- 列出了变量的类型
- 只显示10行
- 只显示有限的列数(与屏幕适应的)
- 高亮
NAs
Create
tibble 有一个很突出的优点:创建时,写在后面的变量可以立即使用前面的变量
# 这种写法如果用 data.table,会报错,表示不知道 b 定义式中的 a 是什么
tibble(
a = runif(1000, 0, 5),
b = 4 + rnorm(1000, mean = 3.2 * a, sd = 1)
) %>% head()#> # A tibble: 6 × 2
#> a b
#> <dbl> <dbl>
#> 1 0.140 4.69
#> 2 4.95 19.4
#> 3 2.24 10.6
#> 4 1.67 8.40
#> 5 3.41 15.8
#> 6 4.75 20.2数据量不大时,可以用tribble()创建
df <- tribble(
~x, ~y, ~z,
"a", 2, 3.6,
"b", 1, 8.5
)Transfer
as_tibble()
Subset
subset 时,即使选取单行或单列,结果也不会降维,仍然是 tibble
Operation
add_column(df, w = 0:1) # 增加一列#> # A tibble: 2 × 4
#> x y z w
#> <chr> <dbl> <dbl> <int>
#> 1 a 2 3.6 0
#> 2 b 1 8.5 1add_row(df, x = "c", y = 9, z = 2.1) # 增加一行#> # A tibble: 3 × 3
#> x y z
#> <chr> <dbl> <dbl>
#> 1 a 2 3.6
#> 2 b 1 8.5
#> 3 c 9 2.1add_row(df, x = "c", y = 9, z = 2.1, .before = 2) # 在第二行,增加一行#> # A tibble: 3 × 3
#> x y z
#> <chr> <dbl> <dbl>
#> 1 a 2 3.6
#> 2 c 9 2.1
#> 3 b 1 8.5print(tibble, n = 10, width = Inf)可以自定义打印的长度和宽度。默认只显示10行,避免输出太长.- 也可以用
options(tibble.print_max=n, tibble.print_min=m)进行全局性设置:如果多于m行,则最多打印出n行。
- 也可以用
- 对于很大的数据表,也可以用
%>% View()或%T>% View()查看 - tibble
不支持行名。
tibble::rownames_to_column(df, var = "rowname")可以将行名转化为一列,tibble::rowid_to_column(df, var = "rowid")将行 index 转化为一列。
若不转置,这个运算根本无法进行。↩︎