管道传输的链式语法
Humoon
2022-05-07
pipeline operator
命令式编程容易出现大量的中间变量,污染全局环境。
可如果写成一系列函数嵌套的形式,又会造成可读性下降
pipeline operator 能够解决这个痛点,使代码更加清晰易读
|>
这是 4.1.0 版本新发布的 base R 管道操作符。
4.2.0 为其设计了 placeholder _,但这个 placeholder
不能单独使用,必须在其出现的参数位置写上 paramter = _
mtcars |> lm(mpg ~ disp, data = _) # data = 不可省略,否则会报错#>
#> Call:
#> lm(formula = mpg ~ disp, data = mtcars)
#>
#> Coefficients:
#> (Intercept) disp
#> 29.59985 -0.04122|> 和 _ 这一套的推广,需要 Rstudio 和
VSCode-R 等 IDE 中快捷键和语法检查的匹配——但它们的更新往往要慢于 R
base
%>% 右向管道操作符
传递对象给右边的函数或表达式。当对象在右边函数的第一个参数时,可以省略这个参数;不是第一个参数时,则可以用.代替。如果是一元函数,甚至可以连()也省掉,只保留函数名。

管道操作符
set.seed(123)
a <- rnorm(10)
a#> [1] -0.56047565 -0.23017749 1.55870831 0.07050839 0.12928774 1.71506499
#> [7] 0.46091621 -1.26506123 -0.68685285 -0.44566197# 由此可见:`*`和`+`其实是两个函数!接收传来的数据流作为自己的第一个参数
a %>%
`*`(5) %>%
`+`(5)#> [1] 2.197622 3.849113 12.793542 5.352542 5.646439 13.575325 7.304581
#> [8] -1.325306 1.565736 2.771690%T>% 左向管道操作符
必须与%>%配合使用。
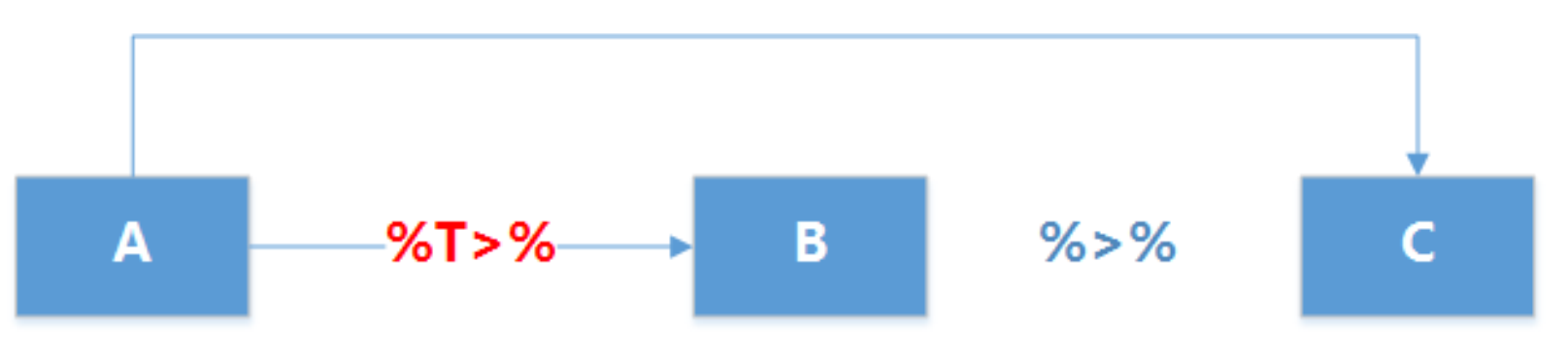
T管道操作符
例1:在数据处理的中间过程,需要打印输出或图片输出(如观察代码是否达到了预设的目的),这时整个过程就会被中断,用向左操作符就可以解决这样的问题。
# 为了提高可读性,%T>% 不换行
rnorm(100) %>%
matrix(ncol = 2) %T>% plot %>%
str()
#> num [1:50, 1:2] 1.224 0.36 0.401 0.111 -0.556 ...%$% 爆炸操作符
一些基础函数只接受向量作为参数,而不接受数据框,爆炸操作符可以绑定数据框,让右侧的函数可以直接使用列名
mtcars %$% cor(disp, mpg)#> [1] -0.8475514相当于
cor(mtcars$disp, mtcars$mpg)#> [1] -0.8475514%<>% 复合赋值操作符
功能与%>%基本一样,多了一项额外的操作,就是把结果写回左侧对象。所以其功能就是运算且更新。
比如,我们需要对一个数据集进行排序,同时需要获得排序的结果,用%<>%就是非常方便的。
现实原理如下图所示,使用%<>%把左侧的数据集A传递右侧的B函数,B函数的结果数据集再向右侧传递给C函数,C函数结果的数据集再重新赋值给A,完成整个过程。
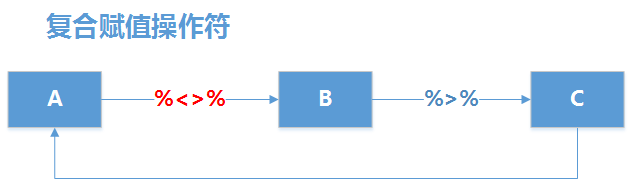
复合赋值操作符
例:定义符合正态分布的100个随机数,计算绝对值,并按从小到大的顺序排序,获得并取前10个数字赋值给x。
set.seed(1)
x <- rnorm(100)
a <- x %>%
abs() %>%
sort() %>%
head(10)
a#> [1] 0.001105352 0.016190263 0.028002159 0.039240003 0.044933609 0.053805041
#> [7] 0.056128740 0.059313397 0.074341324 0.074564983x %<>% abs %>%
sort() %>%
head(10)
x#> [1] 0.001105352 0.016190263 0.028002159 0.039240003 0.044933609 0.053805041
#> [7] 0.056128740 0.059313397 0.074341324 0.074564983%<>%的主要作用是省略一步<-,但会造成变量的改变,程序的稳健性会因此削弱,最好不要用。
流式操作的使用场景
在函数间传递数据
匿名函数function(parameter){...}单独出现时,外面要用括号()括起来
iris %>%
(function(x) {
if (nrow(x) > 2) {
bind_rows(head(x, 1), tail(x, 1)) %>% return()
} else {
return(x)
}
})#> Sepal.Length Sepal.Width Petal.Length Petal.Width Species
#> 1 5.1 3.5 1.4 0.2 setosa
#> 2 5.9 3.0 5.1 1.8 virginica用函数替代运算符
# 本质上,R中的运算符都是函数,故以下两行伪代码等价
fun(sym) <- value
`fun<-`(sym, value) # 上一行是这一行的语法糖| 新函数 | 原操作符1 |
|---|---|
extract(x, index or 'col_name') |
[,即[(x, index/‘col_name’) |
extract2(x, index or 'col_name') |
[[,即[[(x, index’col_name’) |
inset() |
[<- |
inset2() |
[[<- |
set_colnames() |
colnames()<- |
set_rownames() |
rownames()<- |
magrittr::use_series()(可用于list),
dplyr::pull()(不适用于list) |
$ |
| add | + |
| subtract | - |
| multiply_by | * |
| raise_to_power | ^ |
| multiply_by_matrix | %*% |
| divide_by | / |
| divide_by_int | %/% |
| mod | %% |
is_in() |
%in% |
| and | & |
| or | | |
| equals | == |
| is_greater_than | > |
| is_weakly_greater_than | >= |
| is_less_than | < |
| is_weakly_less_than | <= |
| not | ! |
set_names() |
names()<- |
set.seed(1)
x <- rnorm(10)
x#> [1] -0.6264538 0.1836433 -0.8356286 1.5952808 0.3295078 -0.8204684
#> [7] 0.4874291 0.7383247 0.5757814 -0.3053884x %>%
multiply_by(5) %>%
add(5)#> [1] 1.8677309 5.9182166 0.8218569 12.9764040 6.6475389 0.8976581
#> [7] 7.4371453 8.6916235 7.8789068 3.4730581x %>%
`*`(5) %>%
`+`(5)#> [1] 1.8677309 5.9182166 0.8218569 12.9764040 6.6475389 0.8976581
#> [7] 7.4371453 8.6916235 7.8789068 3.4730581x <- 1:10
x %<>% set_names(letters[1:10])
# 作为参数传入函数时,会自动生成副本,x不会被修改,所以必须加赋值命令
x#> a b c d e f g h i j
#> 1 2 3 4 5 6 7 8 9 10x <- 1:10
x %<>% `names<-`(letters[1:10]) # names()<- 在R中执行的真正形式
x#> a b c d e f g h i j
#> 1 2 3 4 5 6 7 8 9 10y <- list(c(1, 2), c("a", "b"))
y %>% `[`(2) # 不能直接用extract(),已被其他包同名函数覆盖#> [[1]]
#> [1] "a" "b"y %>% magrittr::extract(2)#> [[1]]
#> [1] "a" "b"y %>% extract2(2)#> [1] "a" "b"y %>%
extract2(2) %>%
class()#> [1] "character"y %>%
extract2(2) %>%
extract2(2)#> [1] "b"y %>%
map(extract2, 2) %>%
unlist()#> [1] "2" "b"# unlist()拆分成vector,必须是同样的数据类型,那只能是数字退化为字符串
df <- tibble(v1 = 1:26, v2 = letters)
# 完成了列名赋值工作
df %<>% set_colnames(c("id", "name")) %>%
filter(id %>% is_in(1:10)) # 替代 %in%
df#> # A tibble: 10 × 2
#> id name
#> <int> <chr>
#> 1 1 a
#> 2 2 b
#> 3 3 c
#> 4 4 d
#> 5 5 e
#> 6 6 f
#> 7 7 g
#> 8 8 h
#> 9 9 i
#> 10 10 j传递数据给代码块
例:对一个包括10个随机数的向量的先*5再+5,求出向量的均值和标准差,并从小到大排序后返回前5条。
set.seed(1)
a <- rnorm(10)
a %>%
multiply_by(5) %>%
add(5) %>%
{
cat("Mean:", mean(.), "\nVar:", var(.), "\n")
sort(.) %>% head(5)
}#> Mean: 5.661014
#> Var: 15.23286#> [1] 0.8218569 0.8976581 1.8677309 3.4730581 5.9182166# 等价于定义一个函数。还是应该定义函数,增强可读性
display <- function(d) {
cat("Mean:", mean(d), "\nVar:", var(d), "\n")
sort(d) %>%
head(5) %>%
print()
}
a %>%
multiply_by(5) %>%
add(5) %>%
display()#> Mean: 5.661014
#> Var: 15.23286
#> [1] 0.8218569 0.8976581 1.8677309 3.4730581 5.9182166R 中的操作符其实都是函数,只不过是写法上特殊一点的无括号函数。所以在管道操作中,左边函数对右边运算符的替换并不是必须的,因为管道也可以和操作符直接配合,只不过都要用反引号将操作符括起来,显式指明这是一个函数。↩︎