关系数据处理
Humoon
2022-04-20
library("nycflights13")
library("sqldf")关系型数据
关系数据最常见于关系数据库管理系统(relational database management system, RDBMS),该系统几乎囊括了所有的现代数据库。
在处理关系数据时,一般来说,dplyr 包要比 SQL 语言更容易使用1 。
预备:数据表之间的关系
nycflights13 包中有勾稽关系的五张表:
head(airlines, n = 5) # 可以根据航空公司的缩写码查到公司全名#> # A tibble: 5 x 2
#> carrier name
#> <chr> <chr>
#> 1 9E Endeavor Air Inc.
#> 2 AA American Airlines Inc.
#> 3 AS Alaska Airlines Inc.
#> 4 B6 JetBlue Airways
#> 5 DL Delta Air Lines Inc.head(airports, n = 5) # 给出了每个机场的信息,通过faa机场编码进行标识#> # A tibble: 5 x 8
#> faa name lat lon alt tz dst tzone
#> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <chr> <chr>
#> 1 04G Lansdowne Airport 41.1 -80.6 1044 -5 A America/New~
#> 2 06A Moton Field Municipal Airport 32.5 -85.7 264 -6 A America/Chi~
#> 3 06C Schaumburg Regional 42.0 -88.1 801 -6 A America/Chi~
#> 4 06N Randall Airport 41.4 -74.4 523 -5 A America/New~
#> 5 09J Jekyll Island Airport 31.1 -81.4 11 -5 A America/New~head(planes, n = 5) # 给出了每架飞机的信息,通过 tailnum 进行标识#> # A tibble: 5 x 9
#> tailnum year type manufacturer model engines seats speed engine
#> <chr> <int> <chr> <chr> <chr> <int> <int> <int> <chr>
#> 1 N10156 2004 Fixed wing multi ~ EMBRAER EMB-~ 2 55 NA Turbo~
#> 2 N102UW 1998 Fixed wing multi ~ AIRBUS INDU~ A320~ 2 182 NA Turbo~
#> 3 N103US 1999 Fixed wing multi ~ AIRBUS INDU~ A320~ 2 182 NA Turbo~
#> 4 N104UW 1999 Fixed wing multi ~ AIRBUS INDU~ A320~ 2 182 NA Turbo~
#> 5 N10575 2002 Fixed wing multi ~ EMBRAER EMB-~ 2 55 NA Turbo~head(weather, n = 5) # 给出了纽约机场每小时的天气状况#> # A tibble: 5 x 15
#> origin year month day hour temp dewp humid wind_dir wind_speed wind_gust
#> <chr> <int> <int> <int> <int> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 EWR 2013 1 1 1 39.0 26.1 59.4 270 10.4 NA
#> 2 EWR 2013 1 1 2 39.0 27.0 61.6 250 8.06 NA
#> 3 EWR 2013 1 1 3 39.0 28.0 64.4 240 11.5 NA
#> 4 EWR 2013 1 1 4 39.9 28.0 62.2 250 12.7 NA
#> 5 EWR 2013 1 1 5 39.0 28.0 64.4 260 12.7 NA
#> # ... with 4 more variables: precip <dbl>, pressure <dbl>, visib <dbl>,
#> # time_hour <dttm>head(flights, n = 5) # 2013年从纽约市出发的所有336,776次航班的信息#> # A tibble: 5 x 19
#> year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
#> <int> <int> <int> <int> <int> <dbl> <int> <int>
#> 1 2013 1 1 517 515 2 830 819
#> 2 2013 1 1 533 529 4 850 830
#> 3 2013 1 1 542 540 2 923 850
#> 4 2013 1 1 544 545 -1 1004 1022
#> 5 2013 1 1 554 600 -6 812 837
#> # ... with 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>,
#> # tailnum <chr>, origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>,
#> # hour <dbl>, minute <dbl>, time_hour <dttm>5张表之间的关系如下图:

其中,flights居于核心地位
键
用于连接每对数据表的变量称为键。键是能唯一标识观测的变量或变量集合(可能一个表找不到任何单一变量作为键,那么就必须使用多个变量作为键)。键的类型有两种:
主键:唯一标识其所在数据表中的观测。例如,planes$tailnum 是一个主键,因为其可以唯一标识 planes 表中的每架飞机。
外键:唯一标识另一个数据表中的观测。例如,flights$tailnum 是一个外键,因为其出现在 flights 表中,并可以将每次航班与唯一一架飞机匹配(对应 planes 表的 tailnum)。
一个变量既可以是主键(或其一部分),也可以是外键(或其一部分)。例如,origin 是 weather 表主键(year、month、day、hour和origin)的一部分,同时也是 airports 表的外键(对应airport表的faa或name,它们都是airport的主键)。
一旦识别出表的主键,最好验证一下,看看它们能否真正唯一标识每个观测。一种验证方法是对主键进行 count() 操作2,然后查看是否有n大于1的记录:
planes %>%
count(tailnum) %>%
filter(n > 1)#> # A tibble: 0 x 2
#> # ... with 2 variables: tailnum <chr>, n <int>weather %>%
count(year, month, day, hour, origin) %>%
filter(n > 1)#> # A tibble: 3 x 6
#> year month day hour origin n
#> <int> <int> <int> <int> <chr> <int>
#> 1 2013 11 3 1 EWR 2
#> 2 2013 11 3 1 JFK 2
#> 3 2013 11 3 1 LGA 2如果一张表没有主键,有时就需要使用 mutate() %>% row_number() 函数为表加上一个主键3。这种主键称为代理键。
主键与另一张表中与之对应的外键构成关系。
数据表的关系运算:Data Join
合并 join
合并连接可以将两个表格中的变量组合起来,它先通过两个表格的键匹配观测,然后将一个表格中的变量复制到另一个表格中。
一个例子
flights2 <- flights %>%
select(year:day, hour, origin, dest, tailnum, carrier)
head(flights2, n = 5)#> # A tibble: 5 x 8
#> year month day hour origin dest tailnum carrier
#> <int> <int> <int> <dbl> <chr> <chr> <chr> <chr>
#> 1 2013 1 1 5 EWR IAH N14228 UA
#> 2 2013 1 1 5 LGA IAH N24211 UA
#> 3 2013 1 1 5 JFK MIA N619AA AA
#> 4 2013 1 1 5 JFK BQN N804JB B6
#> 5 2013 1 1 6 LGA ATL N668DN DL想要将航空公司的全名加入flights2数据集,你可以通过left_join()函数组合airlines 和 flights2 数据框
flights2 %>%
select(-origin, -dest) %>%
left_join(airlines, by = "carrier")#> # A tibble: 336,776 x 7
#> year month day hour tailnum carrier name
#> <int> <int> <int> <dbl> <chr> <chr> <chr>
#> 1 2013 1 1 5 N14228 UA United Air Lines Inc.
#> 2 2013 1 1 5 N24211 UA United Air Lines Inc.
#> 3 2013 1 1 5 N619AA AA American Airlines Inc.
#> 4 2013 1 1 5 N804JB B6 JetBlue Airways
#> 5 2013 1 1 6 N668DN DL Delta Air Lines Inc.
#> 6 2013 1 1 5 N39463 UA United Air Lines Inc.
#> 7 2013 1 1 6 N516JB B6 JetBlue Airways
#> 8 2013 1 1 6 N829AS EV ExpressJet Airlines Inc.
#> 9 2013 1 1 6 N593JB B6 JetBlue Airways
#> 10 2013 1 1 6 N3ALAA AA American Airlines Inc.
#> # ... with 336,766 more rows# 另一种操作方法
flights2 %>%
select(-origin, -dest) %>%
mutate(name = airlines$name[match(carrier, airlines$carrier)])#> # A tibble: 336,776 x 7
#> year month day hour tailnum carrier name
#> <int> <int> <int> <dbl> <chr> <chr> <chr>
#> 1 2013 1 1 5 N14228 UA United Air Lines Inc.
#> 2 2013 1 1 5 N24211 UA United Air Lines Inc.
#> 3 2013 1 1 5 N619AA AA American Airlines Inc.
#> 4 2013 1 1 5 N804JB B6 JetBlue Airways
#> 5 2013 1 1 6 N668DN DL Delta Air Lines Inc.
#> 6 2013 1 1 5 N39463 UA United Air Lines Inc.
#> 7 2013 1 1 6 N516JB B6 JetBlue Airways
#> 8 2013 1 1 6 N829AS EV ExpressJet Airlines Inc.
#> 9 2013 1 1 6 N593JB B6 JetBlue Airways
#> 10 2013 1 1 6 N3ALAA AA American Airlines Inc.
#> # ... with 336,766 more rows# 但这种方式很难推广到需要匹配多个变量的情况,而且需要仔细阅读代码才能搞清楚操作目的。内连接
inner_join(x, y, by = NULL, copy = FALSE, suffix = c(".x", ".y"),...)
内连接的结果是一个新数据框,其中包含键和两表键以外的列,保留两表均有的行。我们使用by参数告诉dplyr哪个变量是键。
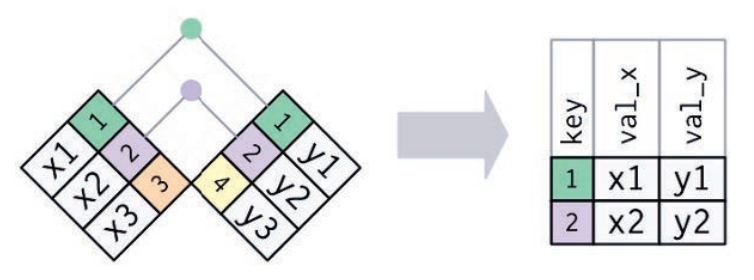
x <- tribble(
~key, ~val_x,
1, "x1",
2, "x2",
3, "x3"
)
y <- tribble(
~key, ~val_y,
1, "y1",
2, "y2",
4, "y3"
)
x %>% inner_join(y, by = "key")#> # A tibble: 2 x 3
#> key val_x val_y
#> <dbl> <chr> <chr>
#> 1 1 x1 y1
#> 2 2 x2 y2内连接最重要的性质是,没有匹配的行不会包含在结果中。这意味着内连接一般不适合在分析中使用,因为太容易丢失观测了。
外连接
内连接保留同时存在于两个表中的观测,外连接则保留至少存在于一个表中的观测。无法充分匹配的观测,会产生NA值。
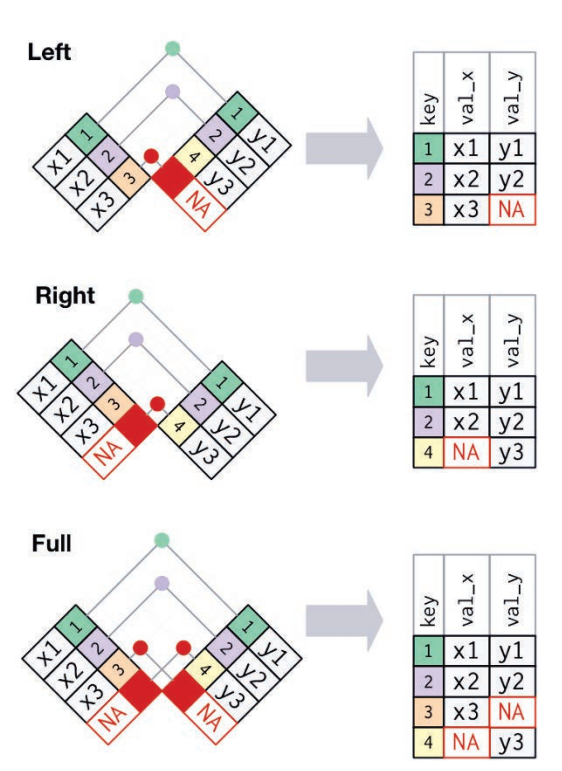
外连接有 3 种类型:左连接,保留 x 中的所有观测;右连接,保留 y 中的所有观测;全连接,保留 x 和 y 中的所有观测。
left_join(x, y, by = NULL, copy = FALSE, suffix = c(".x", ".y"), ...)
right_join(x, y, by = NULL, copy = FALSE, suffix = c(".x", ".y"), ...)
full_join(x, y, by = NULL, copy = FALSE, suffix = c(".x", ".y"), ...)
最常用的连接是左连接:只要想从另一张表中添加新变量,就可以使用左连接,因为它会保留原表中的所有观测,即使它没有匹配。左连接是默认选择,除非有足够充分的理由选择其他的连接方式。
x %>% left_join(y, by = "key")#> # A tibble: 3 x 3
#> key val_x val_y
#> <dbl> <chr> <chr>
#> 1 1 x1 y1
#> 2 2 x2 y2
#> 3 3 x3 <NA>x %>% right_join(y, by = "key")#> # A tibble: 3 x 3
#> key val_x val_y
#> <dbl> <chr> <chr>
#> 1 1 x1 y1
#> 2 2 x2 y2
#> 3 4 <NA> y3x %>% full_join(y, by = "key")#> # A tibble: 4 x 3
#> key val_x val_y
#> <dbl> <chr> <chr>
#> 1 1 x1 y1
#> 2 2 x2 y2
#> 3 3 x3 <NA>
#> 4 4 <NA> y3重复键
一张表有重复键
通常来说,当存在一对多关系时,如果你想要向表中添加额外信息,就会出现这种情况。
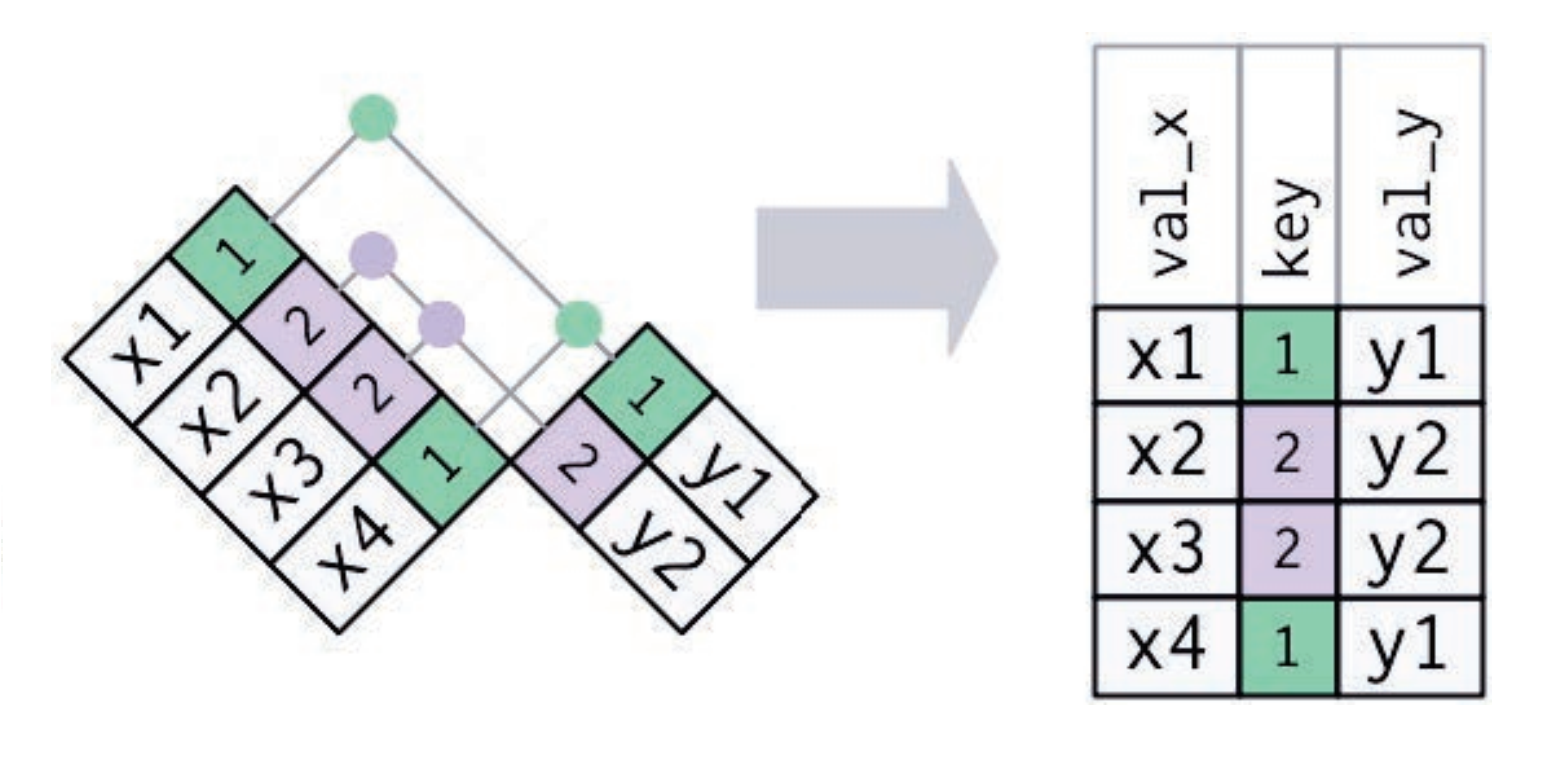
x <- tribble(
~key, ~val_x,
1, "x1",
2, "x2",
2, "x3",
1, "x4"
)
y <- tribble(
~key, ~val_y,
1, "y1",
2, "y2"
)
left_join(x, y, by = "key")#> # A tibble: 4 x 3
#> key val_x val_y
#> <dbl> <chr> <chr>
#> 1 1 x1 y1
#> 2 2 x2 y2
#> 3 2 x3 y2
#> 4 1 x4 y1两张表都有重复键
这通常意味着出现了错误,因为键在任意一张表中都不能唯一标识观测。当连接这样的重复键时,你会得到所有可能的组合,即笛卡儿积。
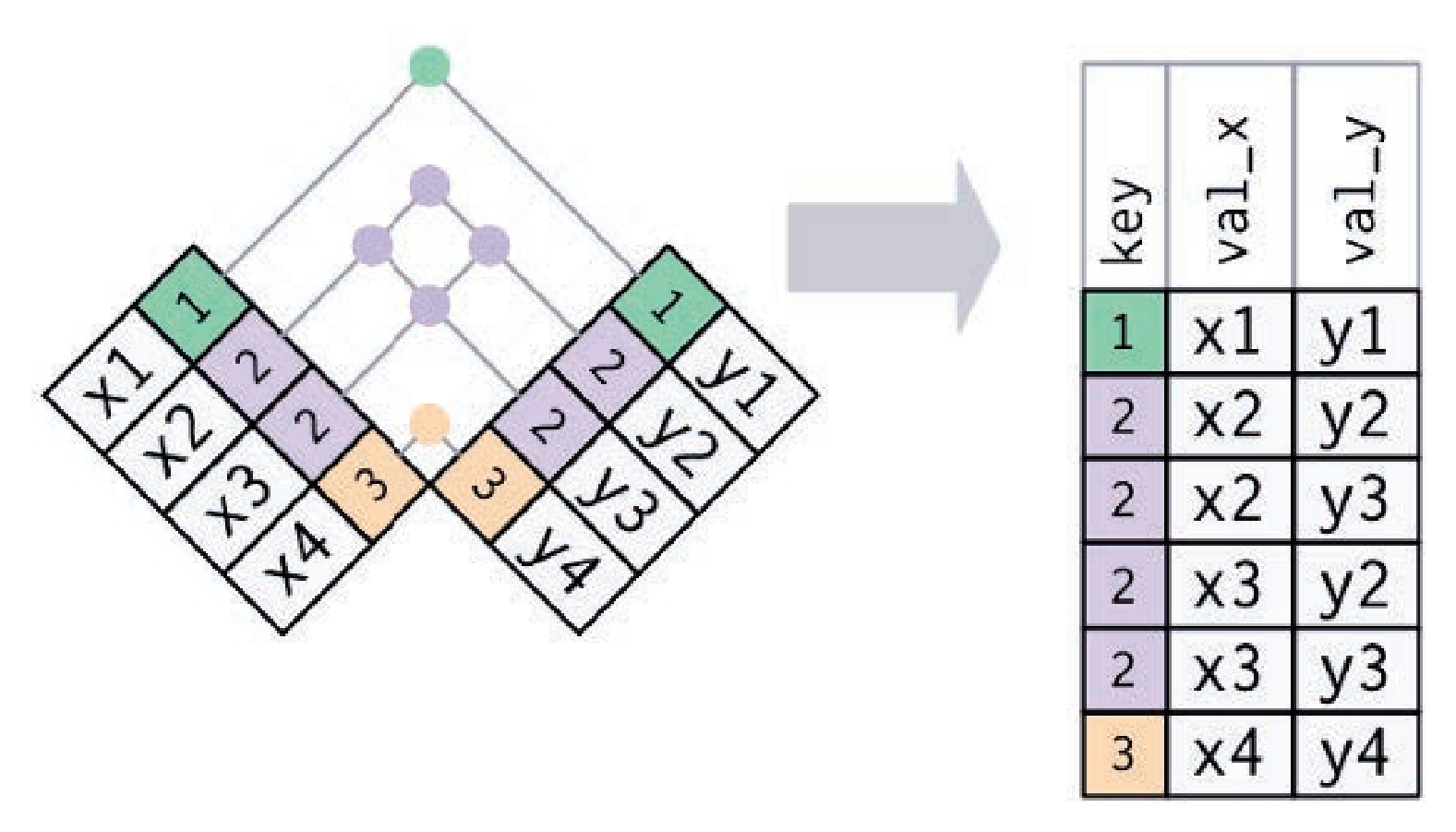
x <- tribble(
~key, ~val_x,
1, "x1",
2, "x2",
2, "x3",
3, "x4"
)
y <- tribble(
~key, ~val_y,
1, "y1",
2, "y2",
2, "y3",
3, "y4"
)
left_join(x, y, by = "key")#> # A tibble: 6 x 3
#> key val_x val_y
#> <dbl> <chr> <chr>
#> 1 1 x1 y1
#> 2 2 x2 y2
#> 3 2 x2 y3
#> 4 2 x3 y2
#> 5 2 x3 y3
#> 6 3 x4 y4筛选 join
筛选连接匹配两表数据的方式与合并连接相同,但不添加新列。筛选连接有两种类型:半连接和反连接。
semi_join(x, y), 半连接。依据key筛选 x 中也在 y 里出现的行(rows of x that have a match in y),不在key中的列不作为筛选标准。anti_join(x, y), 反连接。依据key筛选 x 中但不在 y 里出现的行(rows of x that do not have a match in y)。反连接可用于删除,如x为分词后的文本数据,y为停用词数据)
例:已经找出了最受欢迎的前 10 个目的地(即去那里的航班数最多)
top_dest <- flights %>%
count(dest, sort = TRUE) %>%
head(10)
top_dest#> # A tibble: 10 x 2
#> dest n
#> <chr> <int>
#> 1 ORD 17283
#> 2 ATL 17215
#> 3 LAX 16174
#> 4 BOS 15508
#> 5 MCO 14082
#> 6 CLT 14064
#> 7 SFO 13331
#> 8 FLL 12055
#> 9 MIA 11728
#> 10 DCA 9705现在想要找出飞往这些目的地的所有航班,你可以自己构造一个筛选器:
flights %>%
filter(dest %in% top_dest$dest) %>%
head(n = 5)#> # A tibble: 5 x 19
#> year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
#> <int> <int> <int> <int> <int> <dbl> <int> <int>
#> 1 2013 1 1 542 540 2 923 850
#> 2 2013 1 1 554 600 -6 812 837
#> 3 2013 1 1 554 558 -4 740 728
#> 4 2013 1 1 555 600 -5 913 854
#> 5 2013 1 1 557 600 -3 838 846
#> # ... with 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>,
#> # tailnum <chr>, origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>,
#> # hour <dbl>, minute <dbl>, time_hour <dttm>但这种方法很难扩展到多个变量。例如,假设已经找出了平均延误时间最长的10天,那么你应该如何使用year、month和day来构造筛选语句,才能在flights中找出这10天的观测?此时你应该使用半连接,它可以像合并连接一样连接两个表,但不添加新列,而是保留x表中那些可以匹配4y表的行:
flights %>%
semi_join(top_dest) %>%
head(n = 5)#> # A tibble: 5 x 19
#> year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
#> <int> <int> <int> <int> <int> <dbl> <int> <int>
#> 1 2013 1 1 542 540 2 923 850
#> 2 2013 1 1 554 600 -6 812 837
#> 3 2013 1 1 554 558 -4 740 728
#> 4 2013 1 1 555 600 -5 913 854
#> 5 2013 1 1 557 600 -3 838 846
#> # ... with 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>,
#> # tailnum <chr>, origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>,
#> # hour <dbl>, minute <dbl>, time_hour <dttm>半连接的图形表示如下所示。重要的是存在匹配,匹配了哪条观测则无关紧要。这说明筛选连接不会像合并连接那样造成重复的行。

半连接的逆操作是反连接。反连接保留x表中那些没有匹配y表的行。
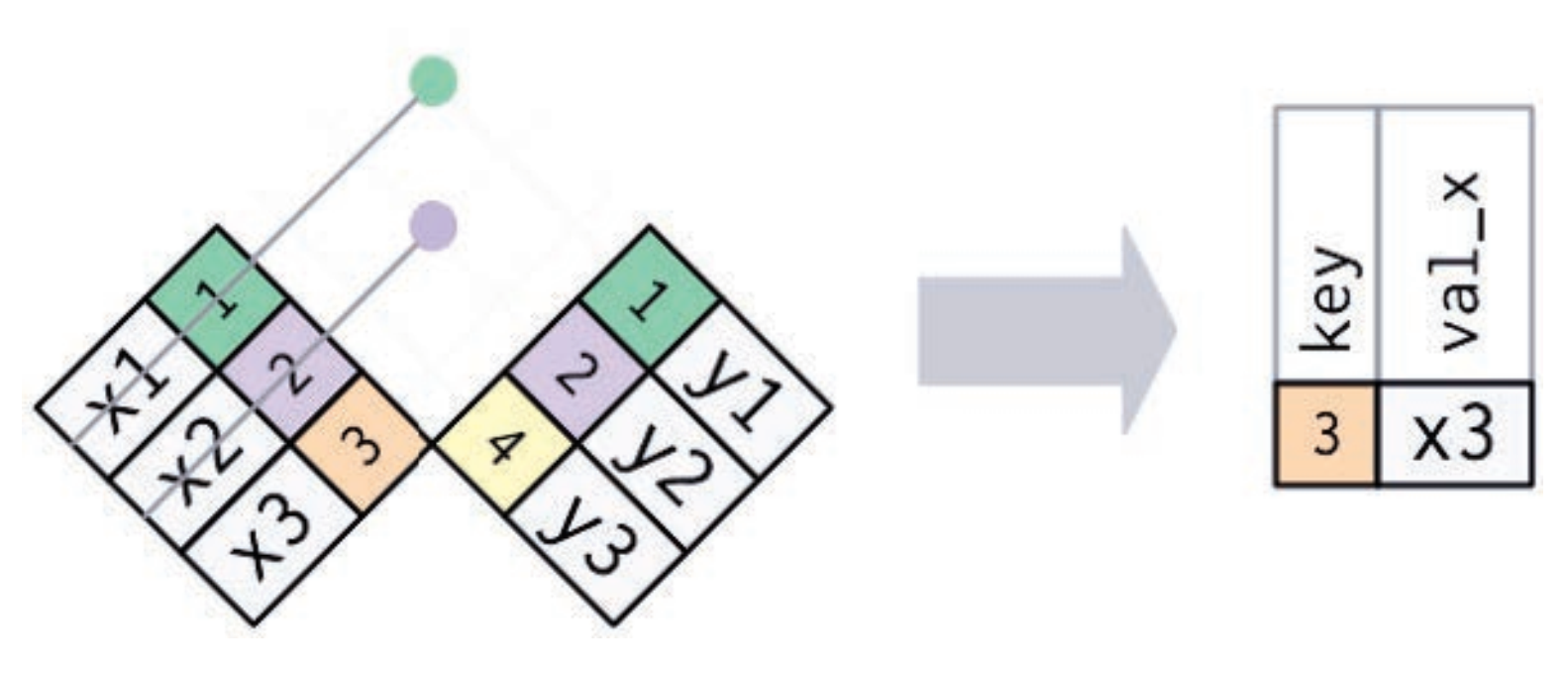
反连接可以用于诊断连接中的不匹配。例如,在连接 flights 和 planes 时,你可能想知道 flights 中是否有很多行在 planes 中没有匹配记录:
flights %>%
anti_join(planes, by = "tailnum") %>%
count(tailnum, sort = TRUE)#> # A tibble: 722 x 2
#> tailnum n
#> <chr> <int>
#> 1 <NA> 2512
#> 2 N725MQ 575
#> 3 N722MQ 513
#> 4 N723MQ 507
#> 5 N713MQ 483
#> 6 N735MQ 396
#> 7 N0EGMQ 371
#> 8 N534MQ 364
#> 9 N542MQ 363
#> 10 N531MQ 349
#> # ... with 712 more rows定义 key
默认 by = NULL
这会使用同时存在于两个表中的所有变量,这种方式称为自然连接。
例如匹配航班表和天气表时使用的就是其公共变量:year、month、day、 hour和origin
flights2 %>%
left_join(weather) %>%
head(n = 5)#> # A tibble: 5 x 18
#> year month day hour origin dest tailnum carrier temp dewp humid
#> <int> <int> <int> <dbl> <chr> <chr> <chr> <chr> <dbl> <dbl> <dbl>
#> 1 2013 1 1 5 EWR IAH N14228 UA 39.0 28.0 64.4
#> 2 2013 1 1 5 LGA IAH N24211 UA 39.9 25.0 54.8
#> 3 2013 1 1 5 JFK MIA N619AA AA 39.0 27.0 61.6
#> 4 2013 1 1 5 JFK BQN N804JB B6 39.0 27.0 61.6
#> 5 2013 1 1 6 LGA ATL N668DN DL 39.9 25.0 54.8
#> # ... with 7 more variables: wind_dir <dbl>, wind_speed <dbl>, wind_gust <dbl>,
#> # precip <dbl>, pressure <dbl>, visib <dbl>, time_hour <dttm>by = c("a", "b", ...)
这种方式与自然连接很相似,但只使用一部分公共变量。
例如,flights和planes表中都有year变量,但是它们的意义不同,因此我们只通过tailnum进行连接:
flights2 %>%
left_join(planes, by = "tailnum") %>%
head(n = 5)#> # A tibble: 5 x 16
#> year.x month day hour origin dest tailnum carrier year.y type
#> <int> <int> <int> <dbl> <chr> <chr> <chr> <chr> <int> <chr>
#> 1 2013 1 1 5 EWR IAH N14228 UA 1999 Fixed wing multi~
#> 2 2013 1 1 5 LGA IAH N24211 UA 1998 Fixed wing multi~
#> 3 2013 1 1 5 JFK MIA N619AA AA 1990 Fixed wing multi~
#> 4 2013 1 1 5 JFK BQN N804JB B6 2012 Fixed wing multi~
#> 5 2013 1 1 6 LGA ATL N668DN DL 1991 Fixed wing multi~
#> # ... with 6 more variables: manufacturer <chr>, model <chr>, engines <int>,
#> # seats <int>, speed <int>, engine <chr>by = c("a" = "b")
这种方式会匹配 x 表中的 a 变量和 y 表中的 b 变量。输出结果中使用的是 x 表中的变量。
例如,如果想要画出一幅地图,那么我们就需要在航班数据中加入机场数据,后者包含了每个机场的位置(lat和lon)。因为每次航班都有起点机场和终点机场,所以需要指定使用哪个机场进行连接:
flights2 %>%
left_join(airports, c("dest" = "faa")) %>%
head(n = 5)#> # A tibble: 5 x 15
#> year month day hour origin dest tailnum carrier name lat lon alt
#> <int> <int> <int> <dbl> <chr> <chr> <chr> <chr> <chr> <dbl> <dbl> <dbl>
#> 1 2013 1 1 5 EWR IAH N14228 UA George~ 30.0 -95.3 97
#> 2 2013 1 1 5 LGA IAH N24211 UA George~ 30.0 -95.3 97
#> 3 2013 1 1 5 JFK MIA N619AA AA Miami ~ 25.8 -80.3 8
#> 4 2013 1 1 5 JFK BQN N804JB B6 <NA> NA NA NA
#> 5 2013 1 1 6 LGA ATL N668DN DL Hartsf~ 33.6 -84.4 1026
#> # ... with 3 more variables: tz <dbl>, dst <chr>, tzone <chr>flights2 %>%
left_join(airports, c("origin" = "faa")) %>%
head(n = 5)#> # A tibble: 5 x 15
#> year month day hour origin dest tailnum carrier name lat lon alt
#> <int> <int> <int> <dbl> <chr> <chr> <chr> <chr> <chr> <dbl> <dbl> <dbl>
#> 1 2013 1 1 5 EWR IAH N14228 UA Newark~ 40.7 -74.2 18
#> 2 2013 1 1 5 LGA IAH N24211 UA La Gua~ 40.8 -73.9 22
#> 3 2013 1 1 5 JFK MIA N619AA AA John F~ 40.6 -73.8 13
#> 4 2013 1 1 5 JFK BQN N804JB B6 John F~ 40.6 -73.8 13
#> 5 2013 1 1 6 LGA ATL N668DN DL La Gua~ 40.8 -73.9 22
#> # ... with 3 more variables: tz <dbl>, dst <chr>, tzone <chr>suffix = c("1", "2")
对于两表有相同列名但又不是key的列,加入后缀进行区分
base::merge()
参数为数据框
base::merge() 可以实现所有 4 种合并连接操作:
| dplyr包 | 基础包merge函数 |
|---|---|
inner_join(x, y) |
merge(x, y) |
left_join(x, y) |
merge(x, y, all.x = TRUE) |
right_join(x, y) |
merge(x, y, all.y = TRUE) |
full_join(x, y) |
merge(x, y, all.x = TRUE, all.y = TRUE) |
dplyr 连接操作的优点是,可以更加清晰地表达出代码的意图:不同连接间的区别确实非常重要,但隐藏在 merge() 函数的参数中了。dplyr 连接操作的速度明显更快,而且不会弄乱行的顺序。
参数为向量
base::merge(x, y) 有一个额外的优点,就是它的参数 x, y
可以是向量,此时效果为对二元数值对 (x, y)
所有可能取值的遍历(返回数据框)。
与之相似的函数是 expand.grid(x, y)
x <- 1:3
y <- letters[1:3]
z <- 1:3
base::merge(x, y)#> x y
#> 1 1 a
#> 2 2 a
#> 3 3 a
#> 4 1 b
#> 5 2 b
#> 6 3 b
#> 7 1 c
#> 8 2 c
#> 9 3 cbase::merge(x, z)#> x y
#> 1 1 1
#> 2 2 1
#> 3 3 1
#> 4 1 2
#> 5 2 2
#> 6 3 2
#> 7 1 3
#> 8 2 3
#> 9 3 3expand.grid(x, y)#> Var1 Var2
#> 1 1 a
#> 2 2 a
#> 3 3 a
#> 4 1 b
#> 5 2 b
#> 6 3 b
#> 7 1 c
#> 8 2 c
#> 9 3 cexpand.grid(x, z)#> Var1 Var2
#> 1 1 1
#> 2 2 1
#> 3 3 1
#> 4 1 2
#> 5 2 2
#> 6 3 2
#> 7 1 3
#> 8 2 3
#> 9 3 3SQL
SQL是dplyr连接操作的灵感来源,二者之间的转换非常简单明了(见下表)。与dplyr相比,SQL支持的连接类型更广泛,因为SQL可以使用除相等关系外的其他逻辑关系
(ON conditional_expression)
来连接两个表(有时这称为非等值连接)。
| dplyr包 | SQL语言 |
|---|---|
inner_join(x, y, by = "z") |
SELECT * FROM x INNER JOIN y USING (z) 或
SELECT * FROM x INNER JOIN y ON conditional_expression |
left_join(x, y, by = "z") |
SELECT * FROM x LEFT OUTER JOIN y USING (z) 或
SELECT * FROM x LEFT OUTER JOIN y ON conditional_expression |
right_join(x, y, by = "z") |
SELECT * FROM x RIGHT OUTER JOIN y USING (z) 或
SELECT * FROM x RIGHT OUTER JOIN y ON conditional_expression |
full_join(x, y, by = "z") |
SELECT * FROM x FULL OUTER JOIN y USING (z) 或
SELECT * FROM x FULL OUTER JOIN y ON conditional_expression |
合并 join 的应用场景
数据分析中许多常见问题,实为关系数据问题。
例:现有国别表,包含country和gdp两个变量,为了进一步分析,需要添加新变量region,说明这些国家所在的地理大区。那么应该如何操作呢?
乍一看,用dplyr::mutate()很难操作,因为新变量要根据country变量的不同取值赋不同的值,这在mutate()的框架下是无法实现的。仔细分析,其实这是一个关系数据问题,因为存在着两个表:country和gdp是一个表,country是主键;country和region的对应关系又是一个表,country还是主键。只不过我们习惯于接受前一个表是数据表,而忽视了后一个对应关系也是一个表。于是,这个添加新变量的过程,便可以表达为两个表通过country这个桥梁合并连接的过程,可以用dplyr::left_join()5 或SQL语言来实现了。
gdp <-
tribble(~country, ~gdp, "德国", "20", "中国", "50", "美国", "70", "日本", "25")
gdp#> # A tibble: 4 x 2
#> country gdp
#> <chr> <chr>
#> 1 德国 20
#> 2 中国 50
#> 3 美国 70
#> 4 日本 25code <-
tribble(~country, ~region, "德国", "欧盟", "中国", "东亚", "美国", "北美", "日本", "东亚", "韩国", "东亚")
code#> # A tibble: 5 x 2
#> country region
#> <chr> <chr>
#> 1 德国 欧盟
#> 2 中国 东亚
#> 3 美国 北美
#> 4 日本 东亚
#> 5 韩国 东亚## 三种等价操作
# 方法1:使用下标索引,以向量为操作单位
join1 <- gdp
join1$region <- "欧盟"
join1[join1$country %in% c("中国", "日本", "韩国"), ]$region <- "东亚"
join1[join1$country == "美国", ]$region <- "北美"
join1#> # A tibble: 4 x 3
#> country gdp region
#> <chr> <chr> <chr>
#> 1 德国 20 欧盟
#> 2 中国 50 东亚
#> 3 美国 70 北美
#> 4 日本 25 东亚# 方法2:dplyr包,以数据框为操作单位
join2 <- left_join(gdp, code, by = "country")
join2#> # A tibble: 4 x 3
#> country gdp region
#> <chr> <chr> <chr>
#> 1 德国 20 欧盟
#> 2 中国 50 东亚
#> 3 美国 70 北美
#> 4 日本 25 东亚# 方法3:sqldf包和sql语言
join3 <- sqldf("select * from gdp left outer join code using (country)")
join3#> country gdp region
#> 1 德国 20 欧盟
#> 2 中国 50 东亚
#> 3 美国 70 北美
#> 4 日本 25 东亚join 前要注意的问题
- 首先,需要找出每个表中可以作为主键的变量。一般应该基于对数据的理解来确定主键,而不是凭经验寻找能作为唯一标识符的变量组合。如果在确定主键时根本没有考虑过其意义,那么就可能步入歧途,虽然可以找出具有唯一性的变量组合,但它与数据间的关系却可能不是真实的。例如,经度和纬度虽然能够唯一标识每个机场,但却不是良好的标识符!
airports %>%
count(alt, lon) %>%
filter(n > 1)#> # A tibble: 0 x 3
#> # ... with 3 variables: alt <dbl>, lon <dbl>, n <int>确保主键中的每个变量都没有缺失值。如果有缺失值,那么这个变量就不能标识观测!
检查外键是否与另一张表的主键相匹配。最好的方法是使用anti_join(),由于数据录入错误,外键和主键不匹配的情况很常见。解决这种问题通常需要大量工作。
数据表的集合运算
观测(行)作为元素,数据表视为观测的集合。集合操作需要两张表具有完全相同的变量。
intersect(),交集,只保留两表中均有的行setdiff(),集合的差,只保留第一个表含有、第二表不含的行union(),并集,保留所有行,但重复的只保留一次union_all(),全集且不舍弃重复行setequal(),检测两个表所含的行是否完全相同(不考虑顺序,像集合一样)
df1 <- tribble(
~x, ~y,
1, 1,
2, 1
)
df2 <- tribble(
~x, ~y,
1, 1,
1, 2
)
intersect(df1, df2)#> # A tibble: 1 x 2
#> x y
#> <dbl> <dbl>
#> 1 1 1union(df1, df2)#> # A tibble: 3 x 2
#> x y
#> <dbl> <dbl>
#> 1 1 1
#> 2 2 1
#> 3 1 2setdiff(df1, df2)#> # A tibble: 1 x 2
#> x y
#> <dbl> <dbl>
#> 1 2 1setdiff(df2, df1)#> # A tibble: 1 x 2
#> x y
#> <dbl> <dbl>
#> 1 1 2