3 贸易、地理和价格初探
3.1 标准化的进口份额
在 (10) 式中取 \(n\) 为 \(i\),然后再相除,得到
\[ \frac{X_{n i} / X_{n}}{X_{i i} / X_{i}}=\frac{\Phi_{i}}{\Phi_{n}} d_{n i}^{-\theta}=\left(\frac{p_{i} d_{n i}}{p_{n}}\right)^{-\theta} \tag{12} \]
左边为 \(i\) 国产品在 \(n\) 国制造业产品支出中的占比除以 \(i\) 国产品在 \(i\) 国造业产品支出中的占比,称为标准化的 \(n\) 国进口中来源于 \(i\) 国的份额(\(n\)’s normalized import share from \(i\),简称为标准化贸易份额)。
标准化贸易份额不会超过1。因为,\(\frac{X_{n i} / X_{n}}{X_{i i} / X_{i}}>1 \Rightarrow \frac{p_{i} d_{n i}}{p_{n}}<1\),若该式成立,\(n\) 国消费的所有产品都可以从 \(i\) 国进口以节省开支(a purchaser in country \(n\) can always buy all her goods in \(i\) at a price index \(p_{i} d_{n i}\)),这与 \(n\) 国选择了最低价格是矛盾的
性质 1:\(p_i/p_n\)↗ 或 \(d_{ni}\)↗ 使标准化贸易份额下降
性质 2:\(\theta\)↗ 反映比较优势减弱,可贸易范围减少,使标准化贸易份额下降
3.2 估计 \(\theta\)
第 (12) 式两边取对数后,\(\theta\) 成为斜率。若有双边贸易价格加成和各国价格水平的数据,便可用这个方程估计 \(\theta\).
3.2.1 计算标准化进口份额
可以使用制造业进出口数据计算标准化贸易份额。
在无贸易障碍的世界,\(d_{ni}=1, \forall n, i\),所有的 \(\Phi\) 都相等,从而所有的价格水平 \(p\) 都相等,则由 (12) 式知标准化的贸易份额将等于 1. 但现实数据显示,该份额从未超过 0.2,且在不同国家对之间差别很大——超过 4 个数量级,如 Figure 1 所示:

这说明,地理(障碍)因素对贸易的影响相当显著。
3.2.2 计算 price measure
价格指数之比:取 50 种产品在样本国家中的零售数据,并进行对数化处理:\(r_{n i}(j) \equiv \ln p_{n}(j)-\ln p_{i}(j)\)。对这 50 种产品的 \(-r_{n i}(j)\) 取平均值,作为 \(\ln \frac{p_i}{p_n}\) 的代理变量(proxy)
\(d_{ni}\) 不是简单的运输成本,而是对所有贸易障碍的衡量,无法直接计算,只能找代理变量。按照本文的理论,只有 \(n\) 国从 \(i\) 国进口的产品才满足 \(p_n(j)/p_i(j)=d_{ni} \Rightarrow r_{ni}(j)=\ln d_{ni}\),\(n\) 国从第三国进口的产品 \(k\) 的价格比从 \(i\) 国进口更便宜,因此有 \(p_n(k)<p_i(k)\cdot d_{ni} \Rightarrow r_{ni}(k)<\ln d_{ni}\)。即 \(\ln d_{ni}\) 是 \(r_{ni}(j)\) 的上限,故有 \(\max\left\{ r_{ni}(j); j \in [0,1]\right\}=\ln d_{ni}\).
为了避免异常值的影响,我们用第二大的 \(r_{n i}(j)\) 作为 \(\ln d_{ni}\) 的代理变量。
将两个代理变量组合起来:
\[ D_{n i} \equiv \max 2_{j}\left\{r_{n i}(j)\right\}-\frac{1}{50}\sum_{j=1}^{50}\left[r_{n i}(j)\right] \tag{13} \]
就是 \(\ln ({p_{i} d_{n i}}/{p_{n}})\) 的代理变量15。
将 \(exp(D_{n i})\) 命名为 price measure,表示一个 \(n\) 国人若全部从 \(i\) 国购买商品,比实际的购买(充分按照比较优势)会贵多少(a buyer who insisted on purchasing everything from source \(i\), relative to the actual price index in \(n\), the price index for a buyer purchasing each goodfrom the cheapest source)。
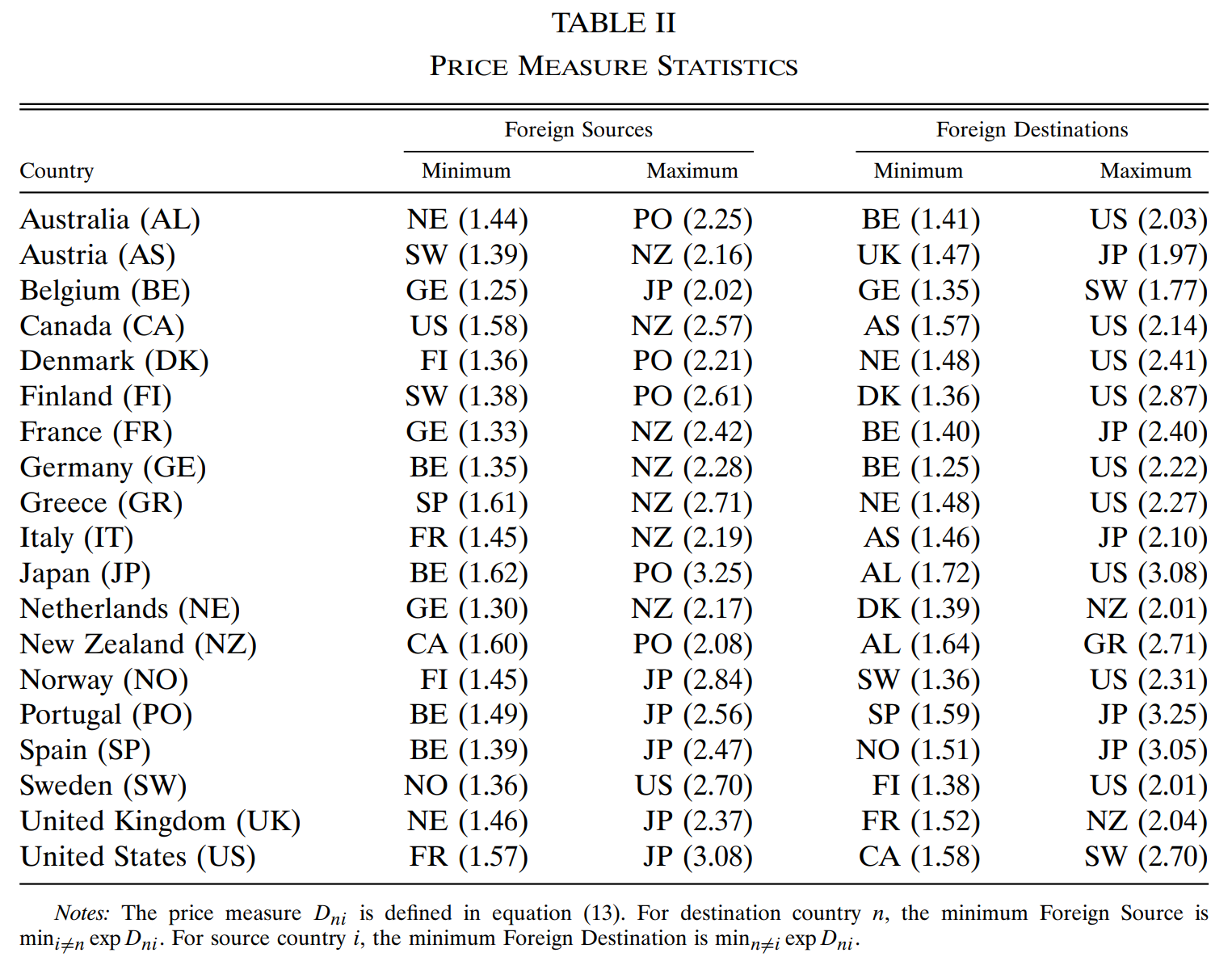
一些计算出的 price measure 值,整理在 Table II 中。
图中法国那一行显示,法国最便宜的货源在德国(第 1 列),从德国购买所有商品只需多支付 33%;最昂贵的货源是新西兰(第 2 列),从新西兰购买所有商品要多支付 142%。一个坚持从法国购买所有商品的海外居民,如果在比利时(第 3 列),将面临最小的惩罚(40%);如果在日本(第 4 列),将面临最大的惩罚(140%)。
最便宜的外国货源通常在附近,而最贵的则在远处。从第 4 列来看,如果要求必须从某个外国来源购买所有的东西,大国通常会受到最大的不利影响(美国、日本出现最频繁)。
3.2.3 参数估计
有了标准化进口份额和 \(D_{n i}\),便可以利用 (12) 式估计 \(\theta\),如 Figure 2 所示:

由于 (12) 式的结构意味着截距为 0,因此可以使用最简单的一阶矩估计:标准化贸易份额的对数取平均值除以 \(D_{ni}\) 的平均值,估计的 \(\theta\) 为 8.28(其他的估计方法得到的 \(\theta\) 值在同一个数量级范围内),这个大小意味着效率分布的标准差为均值的大约 \(17.2\%\).
## 计算生产率 Z_i(j) 的标准差
# 参数,包括 theta 和一系列不同的 T
theta <- 8.28
T_list <- 10^(seq(2, 4, length.out = 7))
## 方法一:理论推导
T_list %>% map_dbl(function(T) {
# Fréchet 概率密度 f(z)
f <- function(z) {
T * theta * z^(-theta - 1) * exp(-T * (z^(-theta)))
}
# 期望,对 zf(z) 的积分
E <- integrate(function(z) {
z * f(z)
}, 0, 25)$value # 积分限制在(0, 25)这个区间,精度足够
# 标准差
sigma <- integrate(function(z) {
(z - E)^2 * f(z)
}, 0, 25)$value %>% sqrt()
# 返回一系列 T 对应的 sigma/E
sigma / E
})#> [1] 0.1722407 0.1722406 0.1722403 0.1722400 0.1722393 0.1722382 0.1722363## 方法二:蒙特卡罗 Simulation
T_list %>% map_dbl(function(T) {
# 用逆变换方法构造一个符合 Fréchet 分布 F(z) 的样本:
# 若t符合[0,1)上的均匀分布,则Z=F^-1(t) 符合 F(z) 分布
t <- runif(10^7)
z <- (log(t) / (-T))^(-1 / theta)
# hist(z,
# breaks = 100, probability = TRUE,
# xlim = c(1, 12), ylim = c(0, 1.8)
# )
sd(z) / mean(z)
})#> [1] 0.1722778 0.1723176 0.1722079 0.1723979 0.1722929 0.1721233 0.1722349\(\max 2\{\}\) 表示第二大。原文中此式有误,勘误表中已经指出,见 TGT Corrections.pdf (google.com).↩︎